
Now that Amazon’s Elastic Block Store is live I thought it’d be helpful to explain all the ins and outs as well as how to use them.
The Basics
EBS starts out really simple. You create a volume from 1GB to 1TB in size and then you mount it on a device (such as /dev/sdj) on an instance, format it, and off you go. Later you can detach it, let it sit for a while, and then reattach it to a different instance. You can also snapshot the volume at any time to S3, and if you want to restore your snapshot you can create a fresh volume from the snapshot.

Reliability
EBS volumes have redundancy built in, which means that they will not fail if an individual drive fails or some other single failure occurs. But they are not as redundant as S3 storage, which replicates data into multiple availability zones; an EBS volume lives entirely in one availability zone. This means that making snapshot backups, which are stored in S3, is important for long-term data safeguarding.
I know that folks at Amazon have thought long and hard how to characterize the reliability of EBS volumes. Here’s their explanation, taken from the EC2 detail page:
Amazon EBS volumes are designed to be highly available and reliable. Amazon EBS volume data is replicated across multiple servers in an Availability Zone to prevent the loss of data from the failure of any single component. The durability of your volume depends both on the size of your volume and the percentage of the data that has changed since your last snapshot. As an example, volumes that operate with 20 GB or less of modified data since their most recent Amazon EBS snapshot can expect an annual failure rate (AFR) of between 0.1% – 0.5%, where failure refers to a complete loss of the volume. This compares with commodity hard disks that will typically fail with an AFR of around 4%, making EBS volumes 10 times more reliable than typical commodity disk drives.
From a practical point of view what this means is that you should expect the same type of reliability you get from a fully redundant RAID storage system. While it may be technically possible to increase the reliability by, for example, mirroring two EBS volumes in software on one instance, it is much more productive to rely on EBS directly. Focus your efforts on building a good snapshot strategy that ensures frequent and consistent snapshots, and build good scripts that allow you to recover from many types of failures using the snapshots and fresh instances and volumes.
Volume Performance
Our performance observations are based on the prerelease EBS volumes, thus some variations on the production systems should be expected. Our prerelease tests were probably running on a small infrastructure with fewer users, but many of these users were also running stress tests, so it’s hard to tell how all this will carry over.
EBS volumes are network-attached disk storage and thus take a slice off the instance’s overall network bandwidth. The speed of light here is evidently 1GBps, which means that the peak sequential transfer rate is 120MBytes/sec. “Any number larger than that is an error in your math.” We see over 70MB/sec using sysbench on a m1.small instance, which is hot! Presumably we didn’t get much network contention from other small instances on the same host when running the benchmarks. For random access we’ve seen more than 1,000 I/O ops/sec, but it’s much more difficult to benchmark those types of workloads. The bottom line though is that performance exceeds what we’ve seen for filesystems striped across the four local drives of x-large instances.
With EBS it is possible to increase the I/O transaction rate further by mounting multiple EBS volumes on one instance and striping filesystems across them. For streaming performance this doesn’t seem worthwhile, as the limit of the available instance network bandwidth is already reached with one volume, but it can increase the performance of random workloads as more heads can be seeking at a time.
Snapshot Backups
Snapshot backups are simultaneously the most useful and the most difficult-to-understand feature of EBS. A snapshot of an EBS volume can be taken at any time. It causes a copy of the data in the volume to be written to S3, where it is stored redundantly in multiple availability zones (like all data in S3). The first peculiarity is that snapshots do not appear in your S3 buckets, thus you can’t access them using the standard S3 API. You can only list the snapshots using the EC2 API, and you can restore a snapshot by creating a new volume from it. The second peculiarity is that snapshots are incremental, which means that in order to create a subsequent snapshot, EBS saves only the disk blocks that have changed since previous snapshots to S3.
The way the incremental snapshots work conceptually is depicted in the diagram below. Each volume is divided up into blocks. When the first snapshot of a volume is taken, all blocks of the volume that have ever been written are copied to S3, and then a snapshot table of contents is written to S3 that lists all these blocks. When the second snapshot is taken of the same volume, only the blocks that have changed since the first snapshot are copied to S3. The table of contents for the second snapshot is then written to S3 and lists all the blocks on S3 that belong to the snapshot. Some are shared with the first snapshot, some are new. The third snapshot is created similarly and can contain blocks copied to S3 for the first, second, and third snapshots.
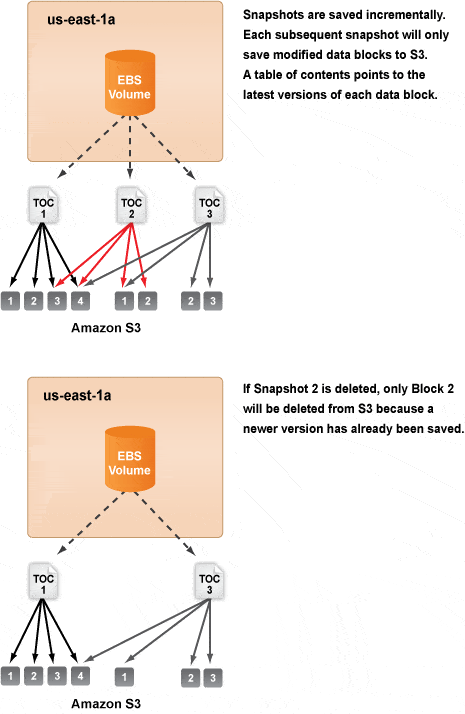
The incremental nature of the snapshots saves time and space. Subsequent snapshots can be fast because only changed blocks need to be sent to S3, and it saves space because you’re only paying for the storage in S3 of the incremental blocks. What is difficult to answer is how much space a snapshot uses, or, to put it differently, how much space would be saved if a snapshot were deleted. If you delete a snapshot, only the blocks that are only used by that snapshot (i.e. are only referenced by that snapshot’s table of contents) are deleted.
Something to be careful about with snapshots is consistency. A snapshot is taken at a precise moment in time, even though the blocks may trickle out to S3 over many minutes. In most situations you want to control what’s on disk vs. what’s in-flight at the moment of the snapshot. This is particularly important when using a database. We recommend you freeze the database, freeze the filesystem, take the snapshot, then unfreeze everything. At the filesystem level we’ve been using XFS for all the large local drives and EBS volumes because it’s fast to format and supports freezing. Thus when taking a snapshot we perform an XFS freeze, take the snapshot, and unfreeze. When running MySQL we also “flush all tables with read lock” to briefly halt writes. All this ensures that the snapshot doesn’t contain partial updates that need to be recovered when the snapshot is mounted. It’s like USB dongles: if you pull the dongle out while it’s being written to, “your mileage may vary” when you plug it into another machine.
Snapshot performance appears to be pretty much gated by the performance of S3, which is around 20MBytes/sec for a single stream. The three big bonuses here are that the snapshot is incremental, that the data is compressed, and that all this is performed in the background by EBS without much affecting the instance on which the volume is mounted. Obviously the data needs to come off the disks, so there is some contention to be expected, but compared to having to do the transfer from disk through the instance to S3 it is like night and day.
Availability Zones
EBS volumes can only be mounted on an instance in the same availability zone, which makes sense when you think of availability zones as being equivalent to data centers. It would probably be technically possible to mount volumes across zones, but from a network latency and bandwidth point of view it doesn’t make much sense.
The way you get a volume’s data from one zone into another is through a snapshot. You snapshot one volume and then immediately create a new volume in a different zone from the snapshot. We have really gotten away from the idea that we’re unmounting a volume from one instance and then remounting it on the next one. We always go through a snapshot for a variety of reasons. The way we think and operate is as follows:
- You create a volume, mount it on an instance, format it, and write some data to it.
- You periodically snapshot the volume for backup purposes.
- If you don’t need the instance anymore, you may terminate it and, after unmounting the volume, you always take a final snapshot. If the instance crashes instead of properly terminating, you also always take a final snapshot of the volume as it was left.
- When you launch a new instance on which you want the same data, you create a fresh volume from your snapshot of choice. This may be the last snapshot, but it could also be a prior one if it turns out that the last one is corrupt.
By creating a volume from the snapshot you achieve two things: one, you are independent of the availability zone of the original volume, and two, you have a repeatable process in case mounting the volume fails, which can easily happen especially if the unmount wasn’t clean.
Of course, in some situations you can directly remount the original volume instead of creating a new volume from a snapshot as an optimization. This applies if the new instance is in the same availability zone, the volume corresponds to the snapshot that we’d like to mount, and the volume is guaranteed not to have been modified since (as for example by a failed prior mount). The best is to think of the volume as a high-speed cache for the snapshot.
Price
Estimating the costs of EBS is tricky. The easy part is the storage cost of $0.10 per GB per month. Once you create a volume of a certain size you’ll see the charge. The $0.10 per million I/O transactions are much harder to estimate. To get a rough estimate you can look at /proc/diskstats on your servers, which will include something like this:
8 160 sdk 9847 77 311900 56570 1912664 3312437 160672914 211993229 0 1597261 212049797 8 176 sdl 333 86 4561 1538 895 51 19002 20131 0 4043 21669
which is just a pile of numbers. You should sum the first number (reads completed) and the fifth number (writes completed) to arrive at the number of I/O transactions (9847+1912664 for /dev/sdk above). This is not 100% accurate but should be close. (I believe subtracting the second and sixth numbers gets you closer yet, but I prefer an over-estimate.) As a point of reference, our main database server is pretty busy and chugs along at an average of 17 transactions per second, which should total to around $4.40 per month. But our monitoring servers, prior to some recent optimizations, hammered the disks as fast as they would go with more than 1,000 random writes per second sustained 24×7. That would end up costing more than $250 per month! As far as I can tell, for most situations the EBS transaction costs will be in the noise, but you can make it expensive if you’re not careful.
The cost of snapshots is harder to estimate due to their incremental nature. First of all, only the blocks written are captured on S3; blocks on the volume that have never been written are not stored on S3. Second, it’s tricky to talk about the cost of a snapshot due to the incremental sharing.
Summing It Up
All in all it’s amazing how simple EBS is, yet how complex a universe of options it opens. Between snapshots, availability zones, pricing, and performance there are many options to consider and a lot of automation to provide. Of course at Flexera we’re busy working out a lot of these for you, but beyond that it is not an overstatement to say that Amazon’s Elastic Block Store brings cloud computing to a whole new level. If you’re using traditional forms of hosting, it’s gonna get pretty darn hard for you to keep up with the cloud, and you’ve probably already fallen behind.




