Constructing a high-availability application in the cloud can seem like a daunting process. The key is to assume that every component of a system will fail at some point and to prepare for that eventuality. Then you can build for failure and automate processes to handle it. Fault-tolerant systems designed for high availability are achievable in the cloud.
High availability (HA) and disaster recovery (DR) strategies are challenges that many companies are attempting to manage. When we advise our customers on designing their architectures for HA in the cloud, there are four tried-and-true steps we typically recommend:
1. Build for server failure
Instances in the cloud — just as in a typical data center — are ephemeral. You need to be prepared for server failure. Building for server failure begins with designing stateless applications that are resilient through a server or service reboot or relaunch.
- Set up auto-scaling so that your application can respond to dynamic traffic patterns based on a set of performance metrics.
- Set up database mirroring, master/slave configurations, and/or priming to ensure data integrity and minimum downtime.
- Use dynamic DNS and static IPs so that components of your application’s infrastructure always have the right context.
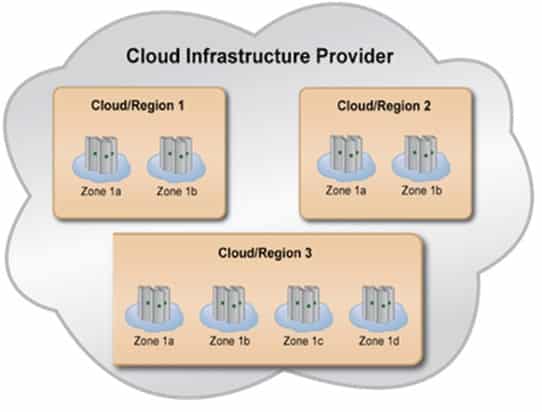
2. Build for zone failure
Sometimes more than just single servers fail — there are power failures, network outages, and lightning strikes. You need to make sure that your applications are prepared for zone failures. Zones (Amazon Web Services refers to them as “availability zones”) are distinct locations that are engineered to be insulated from failures in other zones.
- Spread the servers in each of your application tiers across at least two zones.
- Replicate data across zones. Note that this is usually cheap, though not free.
3. Build for cloud failure
On rare occasions multiple zones in a region can experience outages due to system-wide issues — the April 2011 Amazon Web Services (AWS) outage is a notable example. Each region is an independent system of resources with its own API endpoint — which is how we define cloud here.
To achieve multiple 9s of availability, you will need to have a process in place for cloud failures. Building across clouds can be difficult: APIs, services, and configurations differ. You will need to design your architecture using generic concepts (durable storage) yet deploy using cloud specifics (EBS volumes).
Cloud management systems abstract away these differences and make it easier for you to implement a fault-tolerant strategy by providing reusable building blocks. These building blocks can be used to not only withstand moving across different regions of the same provider, but also across different infrastructure providers.
- Back up or replicate data across regions or providers. Make sure you secure and authenticate your communications across these regions as the traffic will traverse the open Internet.
- Maintain sufficient capacity to absorb zone or cloud failures, using reserved instances if necessary.
- Remember to crawl, then walk: Build high availability across zones and then expand to multiple clouds.
4. Automate and test everything
As you set up your infrastructure to handle server, zone, and cloud failure, you should be automating your processes in the event such a failure occurs. Cloud management systems allow you to execute pre-planned failover processes across servers, zones, and clouds. In an emergency, time is precious, so automate everything.
- Automate backups so that your data is ready whenever disaster strikes.
- Set up monitoring and alerts to identify and pinpoint problems as they occur because you may not receive timely information from your cloud providers.
- Your disaster recovery plan is only good if you test it to make sure it works. By directing high loads to your production servers and disabling your various servers, services, and zones, you can test the ability of your infrastructure to withstand failure.
Cloud infrastructure has made DR and HA remarkably affordable compared to other options. Despite recent highly publicized failures, many organizations successfully run critical services on the cloud when they architect correctly and use the right management tools.




