
Managing data at scale is hard. Organizations today sit on massive, complicated data ecosystems, and the pressure to make data-driven decisions faster keeps growing. That’s what gave rise to concepts like Data Mesh, Data Fabric, Data Lakes and Data Warehouses. Each has its pros and cons. Data Mesh and Data Fabric represent distinct data platform architectures; Data Mesh focuses on decentralizing data ownership, helping data teams manage their own data, while Data Fabric focuses on a unified architecture that integrates and governs data across the organization. Data Lakes and Data Warehouses, on the other hand, serve as storage solutions. Data Lakes is a centralized storage repository that allows for the storage of vast amounts of structured and unstructured data, whereas Data Warehouses store structured, processed data optimized for analytics.
In this article, we will cover everything you need to know about Data Lakes, Data Warehouses, Data Mesh and Data Fabric, providing a clear understanding of each concept and how they compare against one another.
The big four: understanding the basic concepts
Before getting into comparisons, let’s get clear on what each concept actually represents. We’ll look at data mesh, data fabric, data lake and data warehouse through the lens of their architecture, key traits, use cases and trade-offs.
1) What Is Data Mesh?
Data Mesh is a decentralized approach to data architecture that emphasizes domain-oriented ownership and self-serve data infrastructure. It aims to overcome the limitations of centralized data management by distributing data ownership across different business domains and treating data as a product, with dedicated teams responsible for data quality and usability.
The concept of Data Mesh was first introduced in 2019 by Zhamak Dehghani while she was director of emerging technologies at ThoughtWorks. It was a direct response to the scaling failures of centralized data architectures, specifically the bottlenecks created when a single central team is responsible for all data pipelines across an entire organization.
Let’s dive into the main traits of Data Mesh.
- Decentralized data ownership by domain teams
- Data treated as a product, with dedicated owners
- Self-serve data infrastructure for domain teams
- Federated computational governance
- Interoperability through standardization across domains
- Scalability through domain decomposition
The 4 core principles of Data Mesh:

Dehghani defined data mesh through four interdependent principles. Miss one, and the whole model tends to collapse.
1) Domain-oriented data ownership and architecture
Each business domain owns and manages its data. The team closest to the data is responsible for it, removing the dependency on a central team that lacks domain context.
2) Data as a product
Data is treated with the same rigor as a customer-facing product. Domain teams are responsible for the quality, discoverability, usability and reliability of the data they publish. Consumers of that data are treated as customers.
3) Self-serve data platform
A shared, self-serve platform gives domain teams the infrastructure they need to build, deploy and manage data products independently, without relying on a central engineering team for every request.
4) Federated computational governance
Governance is not abandoned in a data mesh; it’s distributed. A federated governance model defines global standards for interoperability, security and compliance. Domain teams operate with autonomy within those standards. Policies are enforced computationally where possible, not manually.
Data Mesh architecture overview
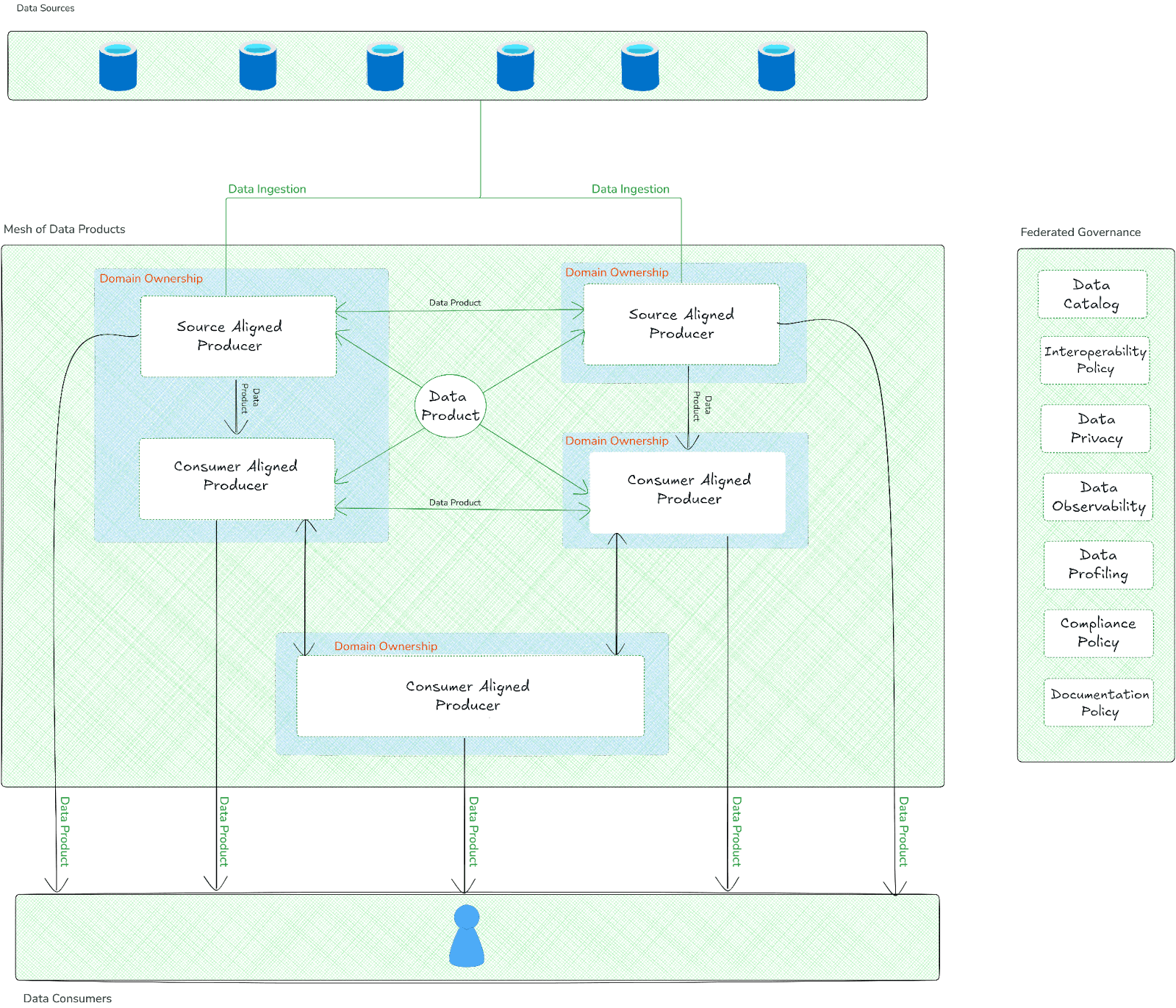
Pros and cons of Data Mesh
Pros:
- Domain teams own their data, which creates accountability and improves quality because those teams actually understand the data
- Reducing dependence on a central team removes a major bottleneck, speeding up data access and pipeline delivery
- The data-as-a-product model encourages cross-domain data sharing, breaking down silos that slow analytics
- Organizations can scale data operations independently across domains without impacting others
- Federated computational governance balances domain autonomy with compliance and interoperability
Cons:
- Transitioning to data mesh requires significant investment in restructuring, tooling and training
- It demands a substantial cultural shift. Domain teams that have never owned data before will push back
- Decentralized ownership can introduce inconsistencies in governance and data standards if the federated model is poorly defined
- There’s no single off-the-shelf vendor solution. You’ll be assembling a stack from multiple tools
- Cross-domain coordination is genuinely complex. Aligning governance standards across many autonomous teams takes ongoing effort
2) What is Data Fabric?
Data Fabric is an architectural design concept that provides a unified, metadata-driven integration and management layer across diverse data environments, including on-premises systems, private clouds and public clouds.
The key word there is metadata. Data fabric doesn’t physically centralize all your data into one place. Instead, it uses active metadata, semantic models, knowledge graphs and machine learning to automate data discovery, integration, governance and delivery. The fabric learns from usage patterns over time and continuously optimizes how data moves through the system.
Data Fabric has some important traits. Here’s what they are:
- Active metadata management at the core
- Automated data discovery and cataloging
- Consistent data governance and security enforcement across environments
- Real-time and batch data processing support
- Hybrid and multi-cloud compatibility
- AI and ML-driven automation for integration and quality
- Federated governance that embeds policy into workflows
Data Fabric architecture overview
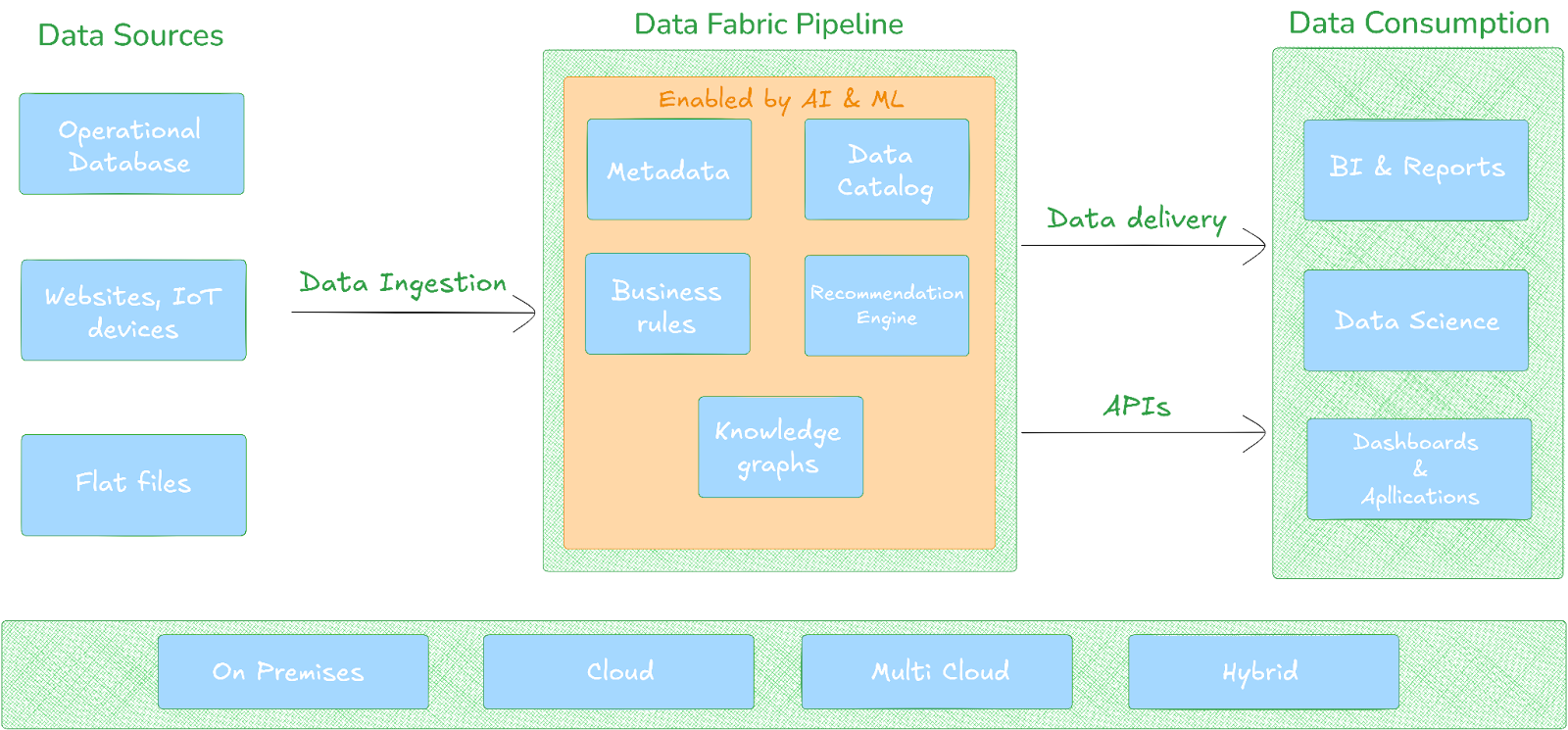
Pros and cons of Data Fabric
Pros:
- Provides a unified management layer over distributed data sources without requiring physical data consolidation
- Embeds governance into workflows through metadata-driven policies, rather than treating it as a separate process
- Enables self-service data consumption at scale by automating discovery and integration
- Reduces query response times significantly by aggregating and caching metadata from previous queries
- AI and ML capabilities continuously improve data quality and governance enforcement
- Encourages asset reuse, which reduces unnecessary duplication
Cons:
- The centralized management layer can create bottlenecks for domain-specific needs and slow responsiveness
- Many of the tools required for active metadata management and augmented data cataloging are still maturing
- Vendors frequently market data fabric as a complete replacement for existing data management practices, which overstates its scope. It’s more accurate to treat it as a complement to other approaches
- Centralized control can restrict innovation at the domain level if teams don’t have enough autonomy to experiment
3) What is Data Lake?
Data Lake is a centralized repository that stores large volumes of data in its raw, native format until it’s needed. Unlike traditional data warehouses, which require data to be structured before ingestion, a data lake accepts everything: structured data from relational databases, semi-structured data like JSON and XML logs, and unstructured data like images, audio files and free text.
Data lakes use a schema-on-read approach. Data is stored without a predefined schema. Structure is applied only when the data is accessed and queried. This means you can ingest data fast without knowing exactly how you’ll use it, which makes data lakes attractive for exploratory analytics, machine learning and data science workloads.
Data lakes typically follow an extract, load, transform (ELT) pipeline model: data is extracted from source systems and loaded into the lake in raw form first. Transformation happens downstream, on demand. Common storage backends include Amazon S3, Azure Data Lake Storage and Google Cloud Storage, often with processing layers like Apache Spark or Databricks on top.
Here are some key traits of Data Lake:
- Stores structured, semi-structured and unstructured data in raw form
- Schema-on-read approach, no upfront structure required
- Highly scalable and cost-effective for large data volumes
- Supports machine learning, advanced analytics and exploratory data science
- Relies on flat, object-based storage rather than folder hierarchies
- Requires strong governance to avoid becoming a “data swamp”
Data Lake architecture overview

Pros and cons of Data Lake
Pros:
- Object storage is cheap, making data lakes far more cost-effective than warehouses for storing large, diverse datasets
- You can ingest data from almost any source, in almost any format
- Schema-on-read lets data scientists explore raw data without waiting for transformation pipelines to be built
- A centralized raw data store reduces duplication across systems and gives teams a single starting point for analysis
- Strong fit for machine learning workflows that need access to large, varied training datasets
Cons:
- Without robust governance, raw data quickly becomes difficult to trust. The “data swamp” problem is real and common
- As a data lake grows, managing metadata, lineage and access controls becomes genuinely complex
- Performance for structured analytical queries is often slower compared to a purpose-built data warehouse
- Data lakes were not originally designed for ACID transactions, which creates consistency challenges for certain workloads
- Some cloud-based data lake implementations create vendor dependency, complicating future migrations
4) What is Data Warehouse?
Data Warehouse is a centralized repository designed specifically for analytical queries and reporting, not transaction processing. It integrates structured data from multiple operational sources, transforming and cleaning it before storage. The result is a consistent, high-quality dataset that provides a “single source of truth” for business intelligence.
Data warehouses use a schema-on-write approach. Data must conform to a predefined schema before it enters the warehouse. This upfront transformation work happens through an extract, transform, load (ETL) pipeline: data is extracted from source systems, transformed to meet schema requirements, then loaded. The trade-off is clear: more effort upfront, but fast, reliable query performance afterward.
Modern cloud-native warehouses like Snowflake, Amazon Redshift and Google BigQuery have significantly expanded what a warehouse can do. They separate compute and storage, support massive scale and increasingly handle ELT workflows as well. Internally, they organize data into schemas using structures like star schema or snowflake schema to optimize query execution.
Here are some key traits of Data Warehouses:
- Stores structured, processed data with enforced schema
- Schema-on-write approach with ETL pipelines
- Optimized for fast SQL queries and complex analytical workloads
- Designed for business intelligence, reporting and decision support
- Strong data quality and consistency through upfront transformation
- Modern cloud implementations separate compute and storage for greater flexibility
Data Warehouse architecture overview
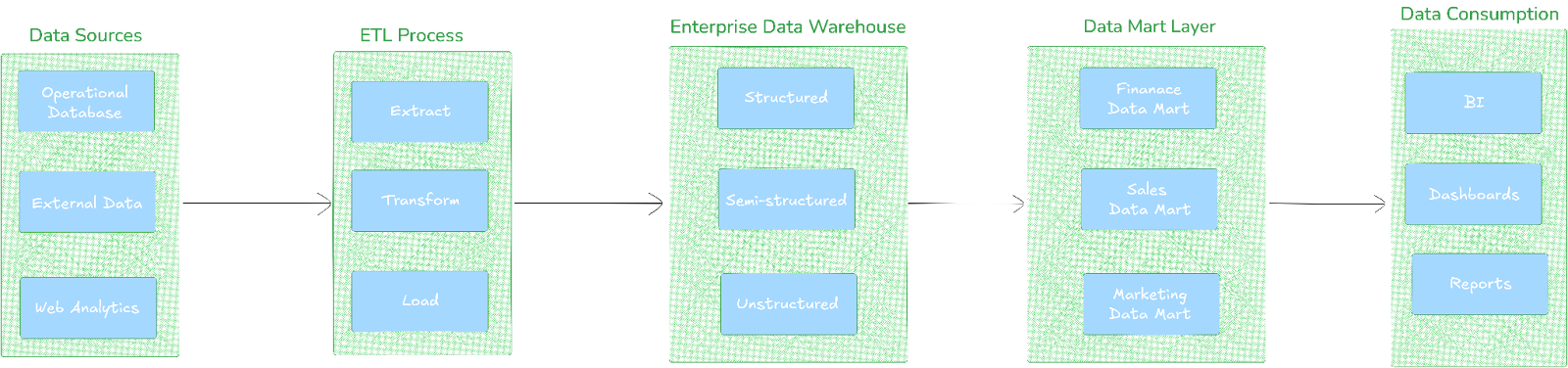
Pros and cons of Data Warehouse
Pros:
- Columnar storage and query optimization make warehouses fast for analytical workloads
- Pre-structured data means business users and analysts can query it directly without data engineering support
- ETL pipelines enforce data quality standards before data is stored, making results reliable
- Strong governance mechanisms, access controls and audit trails are built into most modern platforms
- Cloud-native options like Snowflake and BigQuery offer significant scalability with pay-per-query pricing models
Cons:
- Traditional on-premises warehouse infrastructure requires significant upfront capital investment
- Warehouses handle structured data well but are a poor fit for unstructured or semi-structured data types
- Legacy implementations with tightly coupled compute and storage can struggle to scale as data volumes grow
- ETL pipelines are complex to build and maintain, and changes to source systems often require significant pipeline rework
- Real-time data ingestion is possible in modern warehouses but adds architectural complexity
What is the difference between a Data Warehouse and a Data Lake?
Now, you know the basics of Data Lake vs Data Warehouse—their pros and cons too. Okay, next, let’s see how they differ from each other.
| Data Lake | Data Warehouse |
| Data Lake is a storage repository that holds a vast amount of raw data in its native format until needed. | Data Warehouse is a centralized repository for structured data, designed for business intelligence and analysis. |
| Data Lake can store structured, semi-structured and unstructured data. | Data Warehouse stores structured data only, with predefined schemas. |
| Data Lake uses a schema-on-read approach, where data is stored in its raw format and schemas are applied when the data is accessed. | Data Warehouse uses a schema-on-write approach, where data is cleaned, transformed and structured before being stored. |
| Data Lake typically follows an ELT (Extract, Load, Transform) process, loading raw data first and transforming it when necessary. | Data Warehouse typically follows an ETL (Extract, Transform, Load) process, where data is transformed and cleaned before loading into the warehouse. |
| Data Lake is primarily used by data scientists, engineers and analysts for advanced analytics, machine learning and big data exploration. | Data Warehouse is used by business intelligence professionals and analysts for reporting, data analysis and decision-making processes requiring structured data. |
| Data Lake is highly scalable and cost-effective for storing large volumes of diverse data types, but may incur higher processing costs. | Data Warehouse offers fast query performance and optimized data access, but can be more expensive due to complex infrastructure and maintenance needs. |
| Data Lake allows for the storage and integration of raw data, supporting diverse data types, but may have more complex security requirements. | Data Warehouse integrates and processes data before storage, ensuring high data quality and robust security through centralized storage and strict access controls. |
| Storage costs are fairly inexpensive in a Data Lake vs a Data Warehouse. Data lakes are also less time-consuming to manage, which reduces operational costs. | Data warehouses cost more than Data Lakes and also require more time to manage, resulting in additional operational costs. |
Data Mesh vs Data Fabric, Lake and Warehouse: Comparative Analysis
Before we go into the specifics of each data architecture and data storage solutions, let’s see how these data paradigms compare in terms of scalability, flexibility and governance.
What is the difference between Data Mesh and Data Fabric?
These two architectures may appear similar at first glance, but their approaches to data management could not be more different—let’s look at the fundamental differences between Data Mesh vs Data Fabric.
Data Mesh vs Data Fabric:
| Data Fabric | Data Mesh |
| Data Fabric is a metadata-driven approach for connecting disparate data tools in a cohesive, self-service manner | Data Mesh is a decentralized approach encouraging distributed teams to manage data as they see fit with some common governance |
| Data Fabric is technology-centric, focusing on creating a unified management layer over distributed data sources without centralizing storage | Data Mesh focuses on organizational change, emphasizing domain-oriented data ownership with decentralized storage and management by domain-specific teams |
| It delivers capabilities like data access, discovery, transformation, integration, security, governance, lineage and orchestration, often using APIs and common JSON data format for integration | It promotes domain-oriented architecture with characteristics such as data as a product, self-serve data infrastructure and federated computational governance, with more hands-on coding required for API integration |
| The management in Data Fabric is unified, providing centralized governance and security across various data sources | Data Mesh advocates for federated governance, allowing domain-specific teams to have autonomy while adhering to some central guidelines |
| Data Fabric simplifies data access and management in a heterogeneous environment, integrating various components typically via low-code or no-code API solutions | Data Mesh allows teams to build and manage their own systems based on specific needs, encouraging innovation and flexibility through a bottom-up management style |
| Tools and vendors supporting Data Fabric include Informatica, Talend, Ataccama, Denodo and Google Cloud (Dataplex), offering integrated solutions for data management | Data Mesh is a conceptual framework not tied to specific tools, driven more by organizational practices and how teams manage and govern data |
| Data Fabric is generally used by data stewards, data engineers, data analysts and data scientists to manage data across repositories and platforms | Data Mesh empowers individual teams, including developers and domain-specific groups, to manage and own their data, treating it as a product |
| Data Fabric emerged to simplify the management of data in increasingly complex environments, handling diverse data sources and platforms | Data Mesh emerged to address the usability gap between Data Warehouses and Data Lakes, enhancing real-time data flows and promoting decentralized ownership |
| Data Fabric handles the complexity of data and metadata through a unified, cohesive management approach, which works well with existing data architectures | Data Mesh rectifies the incongruence between Data Lakes and Data Warehouses by reimagining data ownership structures in a decentralized, domain-oriented manner |
What is the difference between Data Mesh and Data Lake?
Data Lakes and Data Meshes are two different ways to handle data. They’re like opposites.
So what exactly are Data Mesh vs Data Fabric?
Zhamak Dehghani introduced Data Mesh to overcome the limitations of traditional data architectures, which often struggle to scale and adapt to the complex needs of modern businesses. A Data mesh is a decentralized sociotechnical approach to sharing, accessing and managing analytical data in complex, large-scale environments—within or across organizations. A Data Lake, on the other hand, is a place to store lots of raw data that can be processed later. It is highly scalable and cost-effective for storing large volumes of diverse data types. While a Data Mesh may utilize a Data Lake as its central data store, it is not solely a data architecture model—it controls how data is managed.
A Data Mesh differs from traditional data infrastructures that centralize storage and processing in a Data Lake. Instead, it promotes distributed data management. Domain-specific teams manage their own data products and pipelines based on their needs, while a universal interoperability layer ensures consistent syntax and data standards across the organization.
Here are some key differences between Data Mesh vs Data Lake
- Data mesh supports self-service data usage; a Data Lake does not.
- Data meshes need stricter rules and standards about how data is formatted and described.
- In a Data Lake architecture, the data team controls and owns all pipelines. In a Data Mesh architecture, domain owners manage their own pipelines.
Let’s look at the differences between Data Mesh vs Data Lake more closely.
Data Mesh vs Data Lake:
| Data Mesh | Data Lake |
| Data Mesh is a decentralized approach to data architecture that emphasizes domain-oriented ownership and self-serve data infrastructure, enabling individual domains to manage and govern their data independently | Data Lake is a centralized repository that stores vast amounts of structured and unstructured data in its original, raw form, typically managed by a central IT team |
| Data Mesh promotes flexibility and scalability by allowing each domain to scale its data infrastructure and pipelines independently based on its specific needs | Data Lake scales vertically, which can become complex as it requires expanding the centralized infrastructure, often leading to significant operational overhead |
| Data Mesh enables domain-specific data governance, where each domain is responsible for data quality, compliance and security within its scope | Data Lake relies on centralized data governance policies, which can be rigid and may not cater to the nuanced requirements of different business domains |
| Data Mesh uses a universal interoperability layer to maintain consistency across domains, ensuring that data from various sources adheres to the same standards and formats | Data Lake integrates data through centralized ETL (Extract, Transform, Load) processes, which can be complex and time-consuming, especially with diverse data sources |
| Data Mesh supports self-service data consumption, allowing domain teams to access and utilize data as needed without relying on a central team | Data Lake typically does not support self-service capabilities as seamlessly, often requiring intervention from central IT or data teams to manage and access data |
| Data Mesh requires strong alignment on data standards such as formatting, metadata fields and governance, ensuring data discoverability and consistency across domains | Data Lake applies centralized data standards uniformly, which can sometimes lead to rigid data structures that are not easily adaptable to specific use cases |
| Data Mesh fosters a distributed, domain-oriented approach to data cataloging, where each domain manages its metadata and ensures the discoverability of its data products | Data Lake relies on a centralized data catalog to manage and navigate the vast amounts of data stored within the lake, which can become difficult to maintain as the data grows |
| Data Mesh typically involves diverse tooling across domains, allowing each domain to use the best tools for their specific needs | Data Lake often relies on a standardized set of tools optimized for large-scale, centralized data processing, which may not be flexible enough for all use cases |
| Data Mesh incurs costs that are distributed across domains, allowing for more optimized resource usage and budgeting based on specific domain requirements | Data Lake involves a centralized cost structure, with significant upfront investments in infrastructure that can be costly to maintain and scale over time |
| Data Mesh implements granular access controls at the domain level, which can be finely tuned to align with specific business rules and security requirements | Data Lake often has more rigid and centralized access controls, which can make it challenging to implement domain-specific security policies |
What is the difference between Data Warehouse and Data Mesh?
Data warehouse is a centralized repository designed to store and manage large volumes of structured data. Traditionally, Data Warehouses were on-premises databases where an organization’s data was integrated into a single source of truth. This approach aimed to create a comprehensive view by linking related data elements that reflect real-world operations. Data is extracted, transformed and loaded (ETL) into the Data Warehouse, where it is organized into data marts for specific use cases, such as marketing or sales analytics.
BUT, the modern concept of a Data Warehouse has evolved significantly. Today, it often refers to cloud-based analytical databases like Snowflake, Redshift and BigQuery. These platforms feature architectures that separate compute and storage, offering greater flexibility and scalability for handling massive amounts of data.
Data Mesh, on the other hand, is a decentralized data architecture that promotes domain-oriented ownership and self-serve data infrastructure. Compared to the centralized approach of traditional Data Warehouses—where a central team manages all data—a Data Mesh empowers individual domains (e.g., marketing, finance, product teams) to own and manage their data pipelines. These domains are connected through a universal interoperability layer that standardizes data governance and ensures consistency across the organization.
But the main question is do Data Warehouses and Data Meshes Work Together? The answer is: Yes, they can. A Data Mesh might use one or more Data Warehouses as part of its system. But they have different goals and ways of working.
Here are a few key differences between Data Mesh vs Data Warehouse.
1) Central vs Spread Out:
- Data Warehouse: One big, central system
- Data Mesh: Spread out across different teams
2) Who’s in Charge:
- Data Warehouse: Usually managed by one central team
- Data Mesh: Each team manages their own data
3) Main Goal:
- Data Warehouse: Create one “source of truth” for all company data
- Data Mesh: Make it easier for teams to use data quickly
4) Flexibility:
- Data Warehouse: Can be slower to change
- Data Mesh: More flexible, easier to adapt quickly
5) Saving Space vs Saving Time:
- Data warehouses: Tries not to repeat data, which saves space.
- Data Mesh: May have some duplicate data to make things faster and easier for teams. Data meshes work well now because storing data is cheaper than it used to be.
Let’s look at the differences between Data Mesh vs Data Warehouse more closely.
Data Mesh vs Data Warehouse:
| Data Mesh | Data Warehouse |
| Data Mesh is decentralized—data is owned and managed by domain-specific teams. Data is distributed across various platforms, with each domain responsible for its data products | Data Warehouse is centralized—data is collected, transformed and stored in a single repository, often using a schema-on-write approach, providing a unified view of organizational data |
| Data Mesh empowers domain teams to handle their data, allowing them to build and manage pipelines that suit their specific needs, leading to faster and more domain-tailored data solutions | Data Warehouse relies on a centralized data team to manage and control data pipelines, ensuring consistent and unified data processing and management across the organization |
| Data Mesh supports scalability by distributing data management across multiple domains and platforms, enabling organizations to scale out their data operations with minimal bottlenecks | Data Warehouse faces scalability challenges, especially as data volumes grow, often requiring significant hardware investments and complex ETL processes to maintain performance |
| Data Mesh offers high flexibility and adaptability, enabling rapid integration of new data sources and changes in data requirements without affecting the entire system | Data Warehouse is less flexible, with changes in data sources or schema often requiring extensive ETL process updates and reconfigurations |
| Data Mesh fosters cross-functional collaboration between domain teams, data engineers and business units, promoting a culture of shared responsibility for data quality and usability | Data Warehouse typically involves less cross-functional collaboration, with a dedicated data team responsible for managing data quality, governance and access controls |
| Data Mesh uses modern technologies like cloud platforms, microservices and containerization to create a flexible, scalable infrastructure that can evolve with organizational needs | Data Warehouse is often built using traditional database technologies and specialized warehousing solutions that may be less adaptable to rapid changes in technology or business requirements |
| Data Mesh places a strong emphasis on data quality within each domain, allowing for tailored data governance and quality standards that align with specific business needs | Data Warehouse centralizes data quality management, which can lead to slower quality improvements and a lack of domain-specific insights |
| Data Mesh is ideal for organizations with complex, diverse data needs that require scalable, flexible and domain-oriented data management solutions | Data Warehouse is best suited for organizations that prioritize a unified, centralized approach to data management, offering consistent and reliable data for business intelligence and analytics |
Do these four approaches work together?
Yes, and in 2026, many mature organizations combine them deliberately.
Use a Data Lake (often built on cloud object storage with formats like Apache Iceberg or Delta Lake) as the raw storage layer. Run a Data Warehouse on top for structured, query-optimized data products. Implement a Data Mesh operating model to distribute ownership of those products to domain teams. Use a Data Fabric as the integration and governance layer that connects everything and makes it discoverable.
These aren’t mutually exclusive choices. The question isn’t which one to pick; it’s which problem you’re trying to solve first.
Want to learn more?
For further reading, consider exploring the following resources:
- Data Mesh Architecture 101—Guide to Its 4 Core Principles
- Data Mesh Wiki
- Databricks Delta Lake 101: A Comprehensive Primer
- What is a Data Warehouse?
- What is a Data Fabric?
- O’Reilly’s Data Mesh Book
- Data Warehouse Toolkit
- Introduction to Data Mesh with Zhamak Dehghani
- What is a Data Lake?
- Data Fabric Explained
- Data Mesh vs Data Fabric vs Data Lake
- Exposing The Data Mesh Blind Side
- How Data Fabric Can Optimize Data Delivery
- Data Fabric vs Data Mesh
- Data Fabric vs Data Mesh: Everything You Need to Know
Conclusion
And that’s a wrap! Choosing between Data Mesh, Data Fabric, Data Lakes and Data Warehouses really depends on what your organization needs, what you already have in place and where you want to go with your data in the long run. Each option has its pros and cons and knowing these can help you make smart decisions about your data setup.
In this article, we have covered:
- What is a Data Lake?
- Pros and cons of Data Lake
- What is a Data Warehouse?
- Pros and cons of Data Warehouse
- What Is Data Mesh?
- Pros and cons of Data Mesh
- What is a Data Fabric?
- Pros and cons of Data Fabric
- Difference between:
- Data Mesh vs Data Fabric
- Data Mesh vs Data Lake
- Data Mesh vs Data Warehouse
…and so much more!
Want to learn more? Reach out for a chat
FAQs
What is Data Mesh?
Data Mesh is a decentralized, sociotechnical approach to data architecture that distributes data ownership to domain teams, treats data as a product and relies on federated computational governance. It was introduced by Zhamak Dehghani in 2019.
What are the 4 core principles of Data Mesh?
The four principles of Data Mesh are: domain-oriented data ownership, data as a product, self-serve data platform and federated computational governance. These four principles are interdependent. Implementing only some of them tends to undermine the others.
What is a Data Lake?
A Data Lake is a centralized repository that stores large volumes of raw data in its native format. It accepts structured, semi-structured and unstructured data and applies structure only when data is queried, using a schema-on-read approach.
What is the main advantage of a Data Lake?
The main advantage is its flexibility. You can ingest data from almost any source, in almost any format, without defining a schema upfront. That makes data lakes well-suited for exploratory analytics, machine learning model training and archiving large volumes of raw data cheaply.
What is a Data Warehouse?
A Data Warehouse is a centralized repository for structured, processed data optimized for analytical queries and business intelligence reporting. It enforces a schema before data is stored and uses ETL pipelines to transform data before ingestion.
What is the primary use case for a Data Warehouse?
Business intelligence, reporting and structured data analysis. Data Warehouses are where you go when you need fast, reliable query performance on clean, well-governed data.
What is Data Fabric?
Data Fabric is an architectural design concept that uses active metadata, semantic models and AI to create a unified management and integration layer over distributed data sources. It doesn’t physically consolidate data but provides consistent governance, discovery and access across environments.
How does Data Mesh improve data quality?
Data Mesh creates direct accountability by placing ownership with the domain teams who generated the data and understand it best. Teams are responsible for the quality, accuracy and reliability of the data products they publish, which changes the incentive structure entirely compared to centralized models.
What are the challenges of implementing Data Fabric?
The main challenges include the maturity of active metadata tooling (many tools are still relatively new), the risk of vendor lock-in with integrated platform suites and the tendency for vendors to overstate data fabric as a replacement for all existing practices rather than a complement.
Can a Data Lake and a Data Warehouse coexist?
Yes. Many organizations run both simultaneously. The Data Lake typically holds raw, diverse data for exploratory and ML workloads. The Data Warehouse holds transformed, structured data for reporting and BI. Modern table formats like Delta Lake and Apache Iceberg increasingly blur this line by adding ACID transactions and warehouse-style query performance directly on top of lake storage.
What is the schema-on-read approach in Data Lakes?
Schema-on-read means data is stored in its raw format without a predefined structure. Structure is applied at query time, when the data is accessed. This contrasts with schema-on-write in Data Warehouses, where structure must be defined and enforced before data is stored.
Is Data Fabric the same as Data Mesh?
No. Data Fabric is a technology-centric architecture pattern for integrating and managing data across distributed environments using metadata automation. Data Mesh is an organizational approach that decentralizes data ownership to domain teams. They address different layers of the problem and can work together.
What is the difference between Data Mesh and Data Fabric?
Data Mesh is about who owns data and how organizations structure accountability. Data Fabric is about how Data Flows and integrates across technical environments. One is an operating model. The other is a technical layer. Gartner describes them as complementary.
What is the difference between Data Mesh and a Data Lake?
A Data Lake is a storage architecture. A Data Mesh is an operating model for data ownership and management. A Data Mesh can use a data lake as part of its infrastructure, but the two solve different problems.
Is Data Mesh better than Data Fabric?
Neither is inherently better. They address different problems at different levels. Data Mesh addresses organizational ownership and accountability. Data Fabric addresses technical integration and metadata management. Many organizations need both.
How does Data Mesh differ from a Data Warehouse?
A Data Warehouse centralizes data into a single repository managed by a central team. A Data Mesh distributes ownership across domain teams. The warehouse can still exist inside a Data Mesh architecture, but domain teams own and operate their own instances.
What is the difference between a Data Warehouse and a Data Lake?
A Data Warehouse stores structured, schema-on-write data optimized for fast queries and BI. A Data Lake stores raw, schema-on-read data in any format, optimized for flexibility and cost-effective storage. The two serve different use cases and are often deployed together.
What is a Data Lakehouse?
A Data Lakehouse is a hybrid architecture that combines the low-cost, flexible storage of a Data Lake with the structure, ACID compliance and query performance of a data warehouse. Platforms like Databricks (Delta Lake) and Apache Iceberg implement this pattern, making the lake-versus-warehouse trade-off less binary than it once was.
When should an organization choose Data Mesh over a centralized approach?
Data Mesh makes sense when a central data team has become a clear bottleneck, when multiple business domains have different and rapidly evolving data needs and when the organization has the maturity to support decentralized ownership with strong interoperability standards. It’s not the right choice for small organizations or early-stage data programs.
Does Data Mesh require a specific technology stack?
No. Data Mesh is technology-agnostic. It’s an organizational and architectural pattern, not a product. Domain teams in a Data Mesh might use Kafka for event streaming, Snowflake as their serving layer, dbt for transformation and a data catalog like Atlan or Alation for discovery. The stack varies by domain. What’s consistent is the governance model and the interoperability standards.




