
Databricks Data + AI Summit 2026 is done. Four packed days in San Francisco. If you missed the live stream or skipped the Moscone Center floor entirely, you missed a lot. It was a pretty eventful few days, with plenty to see and learn. The conference brought together 30,000+ data and AI professionals from 150+ countries for what Databricks calls the world’s largest data and AI event, and the product announcements kept coming from the moment the keynote kicked off.
The summit ran from June 15 to 18, 2026, at Moscone Center, the same venue as the previous year. The main keynote stage opened on June 15, where co-founder and CEO Ali Ghodsi got things started right away. He made one argument and stuck to it: AI doesn’t have an intelligence problem ;it has a context problem. Every major announcement across the two-day keynote program, including Genie One, LTAP, Lakehouse//RT, the Unity AI Gateway and the rest, traced back to that single idea.

Databricks Data + AI Summit 2026 at Moscone Center
Databricks shipped a significant amount of product this year. Sessions were dense. Announcements came fast. This article breaks down every significant launch across all four days and what to expect in the months ahead.
Databricks Data + AI Summit 2026 product announcements summary
Here is a look at everything Databricks announced across the four days.
| Databricks Data + AI Summit 2026 product / feature | Summary | Status |
| Genie One | Agentic AI coworker for business teams, powered by Genie Ontology and connected to 50+ enterprise apps | GA |
| Genie Ontology | Live, self-improving context layer for AI agents; includes OntoRank algorithm | Preview |
| Genie Agents | Turn any Genie One conversation into a reusable, shareable agent | GA |
| Genie Code | AI coding agent built for data engineering and ML workflows, trained on Databricks platform context | GA |
| Genie ZeroOps | Autonomous background agent that monitors pipelines, detects failures, investigates root causes and proposes fixes | Preview |
| Genie App Builder | AI-powered application builder using Genie context and governance | Private preview |
| Agent Bricks (expanded) | Full enterprise agent platform with 100k+ agents built; adds Kimi (Moonshot AI) and Grok (via SpaceX/xAI partnership), managed memory, Document Intelligence and Databricks Sandbox | GA |
| Omnigent | Open source meta-harness that sits above existing agent frameworks, enabling agent composition, collaboration and centralized governance | Open source (Beta managed version) |
| Unity AI Gateway | Runtime governance for all AI: spend caps, smart routing, contextual security policies, MCP server registry, agent tracing via MLflow | GA |
| Unity Catalog (Business Glossary, Domains, Metrics) | Three new semantic capabilities for defining and governing business knowledge | Various previews |
| OpenSharing | Superset of Delta Sharing extending the protocol to AI assets including agents, models and skills; on-premises storage support included | Available (announced June 10) |
| LakeFlow Connect (100+ connectors) | Unified data ingestion with 100+ connectors including community-built | GA |
| ZeroBus Ingest | Fully managed, Kafka-wire-compatible push ingestion API; over 10 GB/s table throughput, sub-5-second latency | GA |
| Spark Declarative Pipelines with real-time mode | Real-time Spark streaming with end-to-end latency as low as 5 ms | GA |
| LakeFlow Designer | No-code, Genie-powered data preparation generating Spark Declarative Pipelines | GA |
| LakeFlow Jobs (50+ integrations) | Fully serverless orchestration with 50+ external system integrations | GA |
| Lakebase (new capabilities) | Cross-cloud/region disaster recovery, git-style branching, autonomous operations | GA |
| Lakebase Search | Hybrid vector + full-text retrieval built natively into Postgres with 32x compression supporting 1B+ vector indexes | Beta |
| LTAP | Lake Transactional Analytical Processing: single copy of data for OLTP + OLAP on open formats | Announced (coming soon) |
| Lakehouse//RT | New SQL warehouse type for millisecond-latency analytics directly on Delta/Iceberg tables, powered by Reyden engine | Beta |
| Reyden engine | New query engine powering Lakehouse//RT, built using ML-driven algorithm selection trained on real query workloads | Beta (powers Lakehouse//RT) |
| LakeBridge | AI-powered, free data warehouse migration tool with improved SQL conversion and assessment tools | Updated (GA) |
| CustomerLake | Agentic customer data platform (CDP) built natively on the lakehouse | GA |
| Lakewatch | Agentic security information and event management (SIEM) on the security lakehouse | GA |
| Panther (acquisition) | Databricks’ third security acquisition: AI SOC platform with 100+ connectors and detection-as-code; integrates into Lakewatch | Intent to acquire announced |
| Databricks Apps (App Spaces, Serverless Micro Apps) | Enterprise app governance and lightweight app deployment | GA / New |
| Databricks Free Edition (expanded) | Five new additions: Genie Code, serverless GPUs, Lakebase, Agent Bricks and LakeFlow Designer | GA |
| AI Runtime | Serverless GPU compute for deep learning and LLM training with multi-node support | Public preview |
| Genie Code for ML | ML-specific variant of Genie Code with deep integration into MLflow, model serving and Unity Catalog | Public preview |
| Genie ZeroOps for ML | Autonomous agent for monitoring and remediating production ML systems | Public preview |
| Iceberg v3 | Managed Iceberg tables now GA in Databricks Runtime; unifies data files across Delta and Iceberg at the storage layer | GA |
| Genie in Microsoft Teams and M365 Copilot | Tag Genie in a Teams thread to get Unity Catalog-governed answers from the Databricks lakehouse | Beta |
| Azure Databricks Excel Add-in | Driverless analytics directly inside Excel with write-back support | Public preview |
Databricks Data + AI summit Day 1 (June 15) — context, cost, control and choice
Day 1 packed in major announcements. Ali Ghodsi opened with a keynote that ran well over an hour. He laid out four enterprise AI challenges, context, cost, control and choice, and then announced product after product to address each one. LakeFlow reached 100+ connectors with three capabilities going GA simultaneously. Iceberg v3 moved to GA. Lakebase introduced cross-cloud and cross-region disaster recovery along with sub-second branching. A new query engine called Reyden powers Lakehouse//RT, a new real-time SQL warehouse type entering beta. LTAP, a new architecture combining transactional and analytical workloads on a single copy of lake storage, was announced as coming soon. The Genie suite expanded with Genie One, Genie Agents, Genie Code, Genie ZeroOps and Genie App Builder, all powered by a new context layer called Genie Ontology. Unity AI Gateway became the governance backbone for all AI spend and agent activity. CustomerLake, an agentic customer data platform, and Lakewatch, an agentic SIEM, also made their summit debuts, tied to the announced acquisition of Panther.
Featured speakers on day 1 of Databricks Data + AI Summit 2026:
- Ali Ghodsi (co-founder & CEO, Databricks)
- Ryan Blue (original creator of Apache Iceberg, co-founder of Tabular)
- Ken Wong (senior director, Genie & AI/BI, Databricks)
- Elise Georis (product manager, Genie, Databricks)
- Magesh Bagavathi (global chief data & AI officer, PepsiCo)
- Arsalan Tavakoli-Shiraji (co-founder & SVP field engineering, Databricks)
- Bilal Aslam (senior director, LakeFlow, Databricks)
- Reynold Xin (co-founder, Databricks)
- Nikita Shamgunov (VP engineering, Databricks, co-founder of Neon)
- Federico Cohen Freue (EVP AI & data operations, Mastercard)
- Greg Brockman (president, chairman & co-founder, OpenAI)
- Patrick Wendell (co-founder & VP engineering for AI, Databricks)
- Holly Smith (developer relations, Databricks)
Databricks Co-founder and CEO Ali Ghodsi started Day 1 with a keynote focused on one main point: AI doesn’t struggle with intelligence; it struggles with context. Every product update he shared during the session backed this idea.

Ali Ghodsi, co-founder and CEO, Databricks, delivering his opening keynote at Data AI Summit 2026
The summit itself set a new attendance record. More than 30,000+ data and AI professionals attended in person from 150+ countries, with tens of thousands more watching virtually. Ghodsi called it “the largest data and AI conference in the world”.
He opened by emphasizing Databricks’ commitment to open source. Apache Spark now has over three billion downloads a year, he noted, and remains foundational to the platform. He also previewed a new open source project called Omnigent, created by co-founder Matei Zaharia, which he covered in detail during Day 2.
The AGI Debate
In a moment of audience interaction, Ghodsi asked how many attendees believed AGI had already arrived. About 90 percent said no. Ghodsi disagreed.

Ali Ghodsi polling the audience at Databricks Data + AI Summit 2026 on whether AGI has already arrived
He made the case by pointing to the definition of AGI from his time doing research at UC Berkeley’s AMPLab around 2009. By that standard, he argued, today’s frontier models have already cleared the bar by a wide margin.
To make it concrete, he asked the audience to solve a specific math problem: “Compute the reduced 12-th dimensional Spin Bordism of the classifying space of the Lie group G2 “. Only one person raised their hand. He then pointed out that “all the frontier agents and AIs today can solve this”.

Ghodsi presenting a complex math problem on screen to the Data + AI Summit 2026 audience to demo AI’s reasoning capability
His conclusion: “AI does not have an intelligence problem right now. The problem is that AGI is not really permeating our organizations”.
The four critical challenges for enterprise AI
Ghodsi organized the rest of his keynote around four challenges he said Databricks is working to solve:
1) Context
2) Control
3) Cost
4) Choice
He was candid about where things stand. “I’m not going to say we’ve completely solved it. But at least we’re making some big leaps towards solving these four things”.
Here’s what he announced.
LakeFlow: 100+ connectors and three new GA features
Ghodsi opened the product section with LakeFlow updates. LakeFlow now has more than 100 connectors, connecting to enterprise systems like Salesforce, Workday, NetSuite, plus external sources like Google Analytics, document repositories and more.
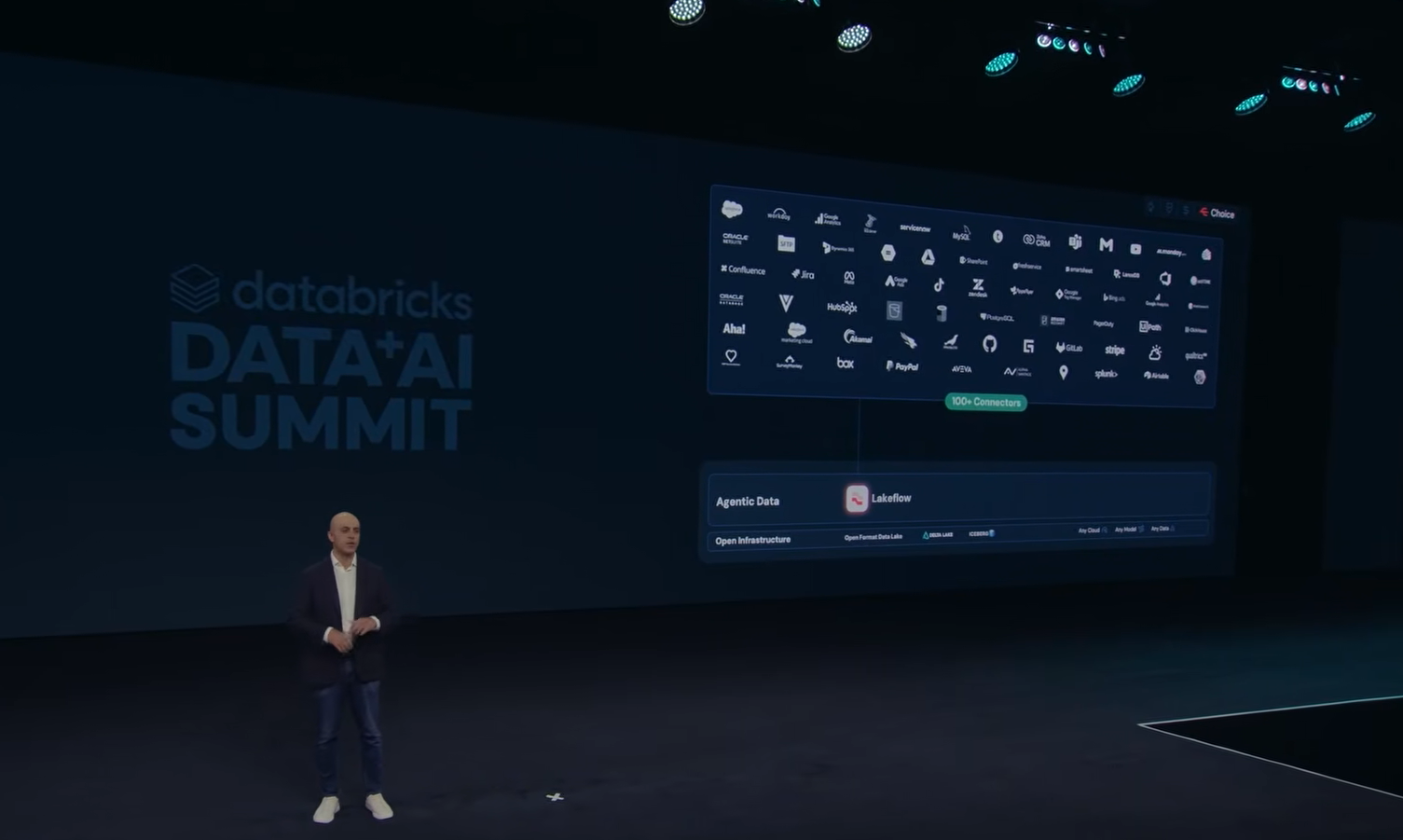
Ali Ghodsi presenting LakeFlow’s 100+ connector milestone on the main keynote stage at Databricks Data + AI Summit 2026
Three LakeFlow capabilities reached GA at the same time:
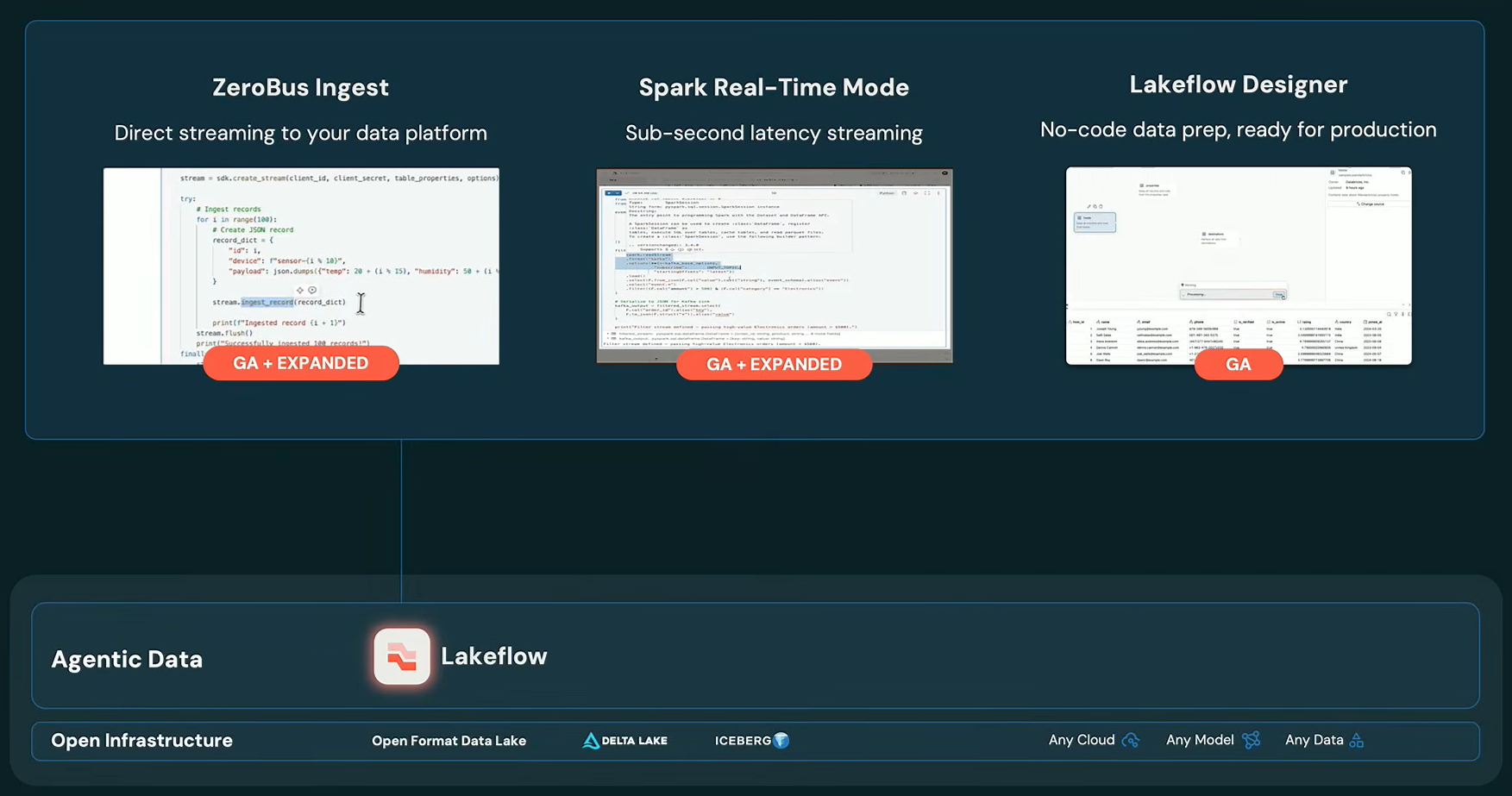
ZeroBus, Spark Realtime Mode and LakeFlow Designer all hit GA, as presented by Ghodsi at Databricks Data + AI Summit 2026 (Source: Databricks Data + AI Summit 2026)
1) Zerobus is now GA. ZeroBus is Databricks’ answer to Apache Kafka when the lakehouse is your sole sink. Instead of running and managing your own message bus, ZeroBus offers a push-based API that handles high-rate, small-row event data and lands it directly into open Delta tables on your lakehouse. It delivers sub-5-second latency with over 10 GB/s of aggregate throughput to a single table, supporting thousands of concurrent clients. Databricks has also added Kafka-Compatible APIs (in beta), so existing Kafka producers can point at ZeroBus with no code changes required.
2) Spark Declarative Pipelines with Real-Time Mode (RTM) reached GA. Historically, Spark’s micro-batch model kept end-to-end streaming latency at roughly one second. RTM changes that. By supporting continuous processing within Spark Declarative Pipelines, RTM achieves as low as 5 ms latency for time-critical workloads such as fraud detection and real-time personalization, while using the same Spark APIs teams already know. Organizations that relied on Apache Flink for sub-second latency can now handle many of those workloads directly in Spark, with no separate engine to operate.
3) LakeFlow Designer is now GA. LakeFlow Designer is a visual, AI-powered, no-code data engineering tool. You describe the transformation you want in natural language, specify the tables to join and Genie builds the result visually. Under the hood, Designer generates Spark Declarative Pipelines, so everything it produces is open-source Spark, fully inspectable and version-controllable. Ghodsi compared the experience to Alteryx, but without the proprietary pipeline lock-in.
Iceberg v3 and the Delta Lake format question
Ghodsi then brought Ryan Blue onto the stage. Blue created Apache Iceberg and co-founded Tabular, which Databricks acquired. The conversation addressed the long-running question about Delta Lake vs Iceberg directly.

Ryan Blue, creator of Apache Iceberg, in conversation with Ali Ghodsi about Iceberg v3 and format unification at Databricks Data + AI Summit 2026
Blue’s position has been consistent for years: “No one should have to care about formats. You should be able to use whatever tools you want with all of your data”. Ghodsi agreed.
The headline announcement: Iceberg v3 support is now generally available in Databricks Runtime with managed Iceberg tables. Technically, Iceberg v3 introduces deletion vectors, row lineage tracking and the VARIANT data type, all with implementations compatible across Delta Lake, Apache Parquet and Apache Spark. The result: the physical Parquet data files on disk are now shared between Delta and Iceberg tables. If you have data in Delta format and data in Iceberg format, the storage layer is unified. You can interoperate across formats without rewriting data files.
Blue explained what’s still to come: “V3 is the unified data layer. You no longer have to rewrite any data files to share them across Delta and Iceberg tables”. The next milestone is Iceberg v4, which will unify the metadata layer as well, completing the convergence. Blue said the target is sometime in Q4 2026 and that work is being done jointly as Delta 5 and Iceberg v4.
Ghodsi’s summary: “It doesn’t matter if it’s in Delta or Iceberg. We don’t care. It’s actually the same now”.
Lakehouse updates and LakeBridge
Databricks’ SQL lakehouse has accumulated more than 110 new features over the past year, many focused on helping organizations migrate from legacy data warehouses. SQL AI functions have been among the most popular additions, letting teams call LLM operations such as sentiment analysis, entity extraction and predictions directly inside SQL queries at scale against tabular data.
Ghodsi also confirmed that LakeBridge, the automated AI-powered data warehouse migration tool first announced at the 2025 summit, has matured significantly. It now handles migrations from both on-premises and cloud data warehouses more effectively, with improved SQL conversion accuracy and better assessment tooling. It remains free to use.
A new query engine: Reyden
Ghodsi teased a new query engine called Reyden, built for workloads requiring millisecond-range latency at high concurrency. He described it as a significant performance leap and pointed to co-founder Reynold Xin’s later keynote segment for the full architecture and benchmark story. Reyden stands for “Reynold’s dream engine”, as Ghodsi revealed on stage.

Ali Ghodsi announcing a new query engine called Reyden at Databricks Data + AI Summit 2026 – Databricks Summit 2026
Introducing Lakebase
One of the major architecture announcements was Lakebase. Databricks built Lakebase on open source PostgreSQL, decoupling compute from storage so that the transactional data sits on the same open lakehouse storage as everything else, governed by Unity Catalog.
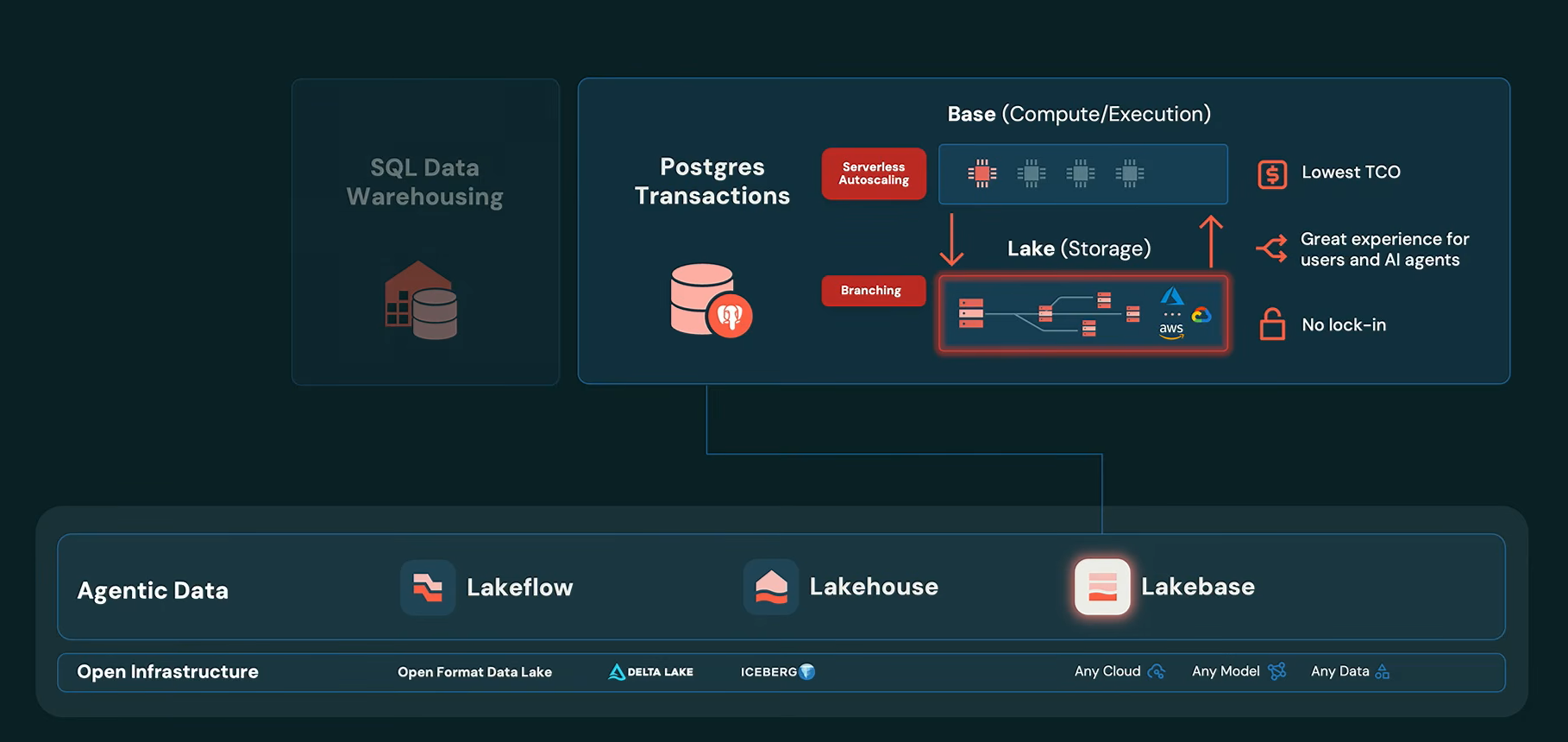
Architecture diagram of Databricks Lakebase showing compute separated from lake storage, as presented by Ali Ghodsi at Databricks Data + AI Summit 2026 (Source: Databricks Data + AI Summit 2026)
The immediate practical benefit is serverless autoscaling, including the ability to scale down to zero when a database isn’t in use. “This was not possible before”, Ghodsi said. “Others had specialized storage, but this is just sitting in open source format on your lake”. Scaling up and down takes less than a second. The result is a significant reduction in total cost of ownership for organizations running large numbers of database instances, because you pay only for cheap lake storage when workloads are idle.
The feature Ghodsi spent the most time on was branching. Lakebase branching uses a copy-on-write mechanism: the actual data stays in one place on the lake, and Lakebase tracks only the deltas between branches. When you make a change to one branch, it’s recorded independently without touching the others. A branch takes about 500 milliseconds. Rollback to an earlier snapshot is equally fast.
Why does this matter for enterprises? Most organizations run thousands of database instances for production, staging, user acceptance testing and R&D environments. That means thousands of data copies, thousands of instances to manage and substantial overhead. Branching collapses this to one logical dataset with multiple branches, cutting both total cost of ownership and operational complexity.
The benefit for agents is even more pointed. Agents can branch out, try something against production data and roll back instantly if something goes wrong, without touching the primary environment. “They don’t want to wait 10 minutes on a database to come up”, Ghodsi said.
Ghodsi also previewed LTAP (Lake Transactional Analytical Processing), a major architecture announcement that Reynold Xin covered later in the day.
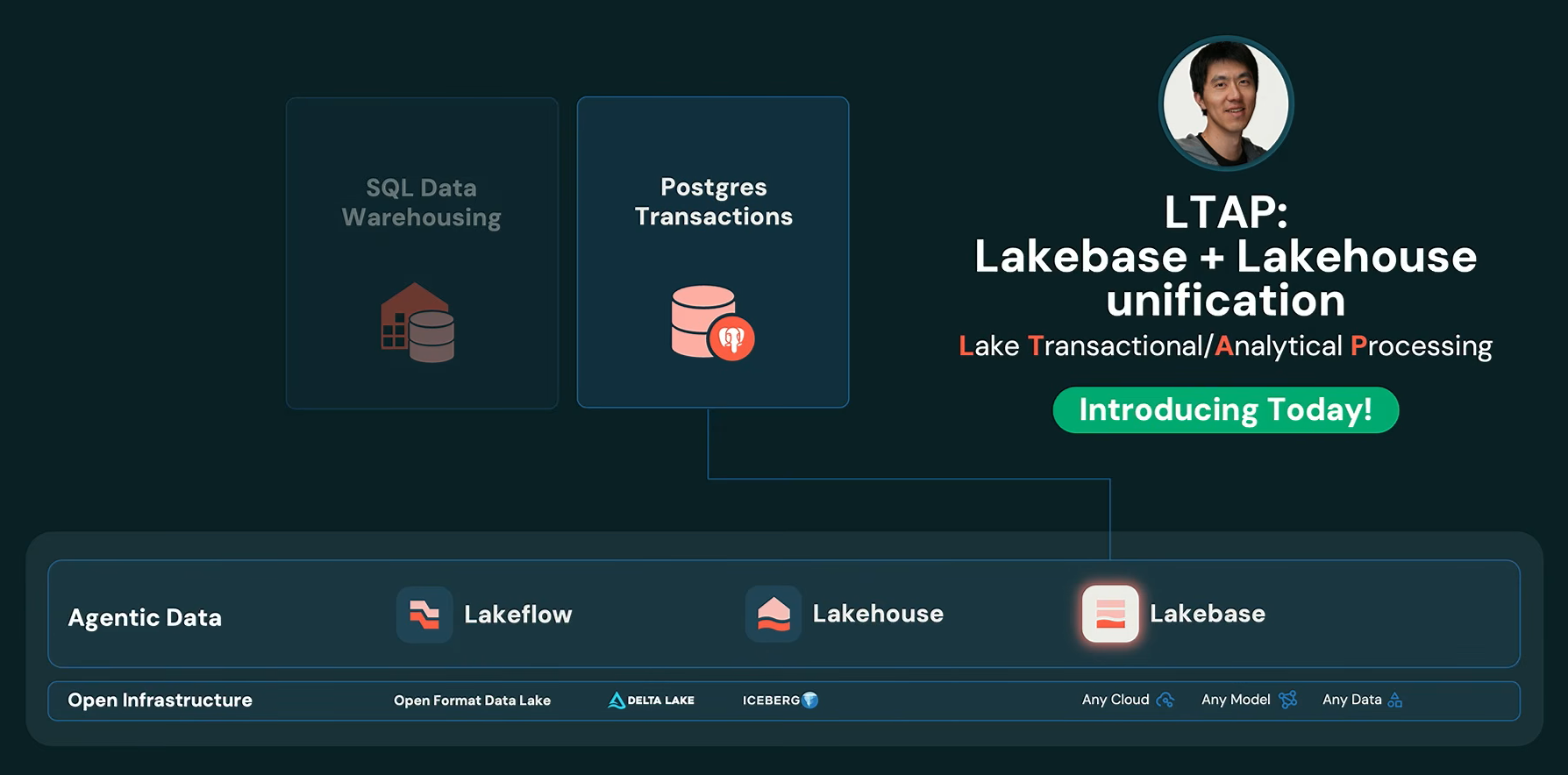
Databricks LTAP (Lakebase and Lakehouse Transactional and Analytical Processing), as presented by Ali Ghodsi at Databricks Data + AI Summit 2026 (Source: Databricks Data + AI Summit 2026)
Unity Catalog AI Gateway
One of the most immediately practical announcements was Unity AI Gateway, a new component of Unity Catalog. Ghodsi was direct about why it exists: AI costs are escaping governance controls at most organizations, and agentic workloads are making that worse.

Ali Ghodsi announcing Unity AI Gateway at Databricks Data + AI Summit 2026 – Databricks summit 2026
Unity AI Gateway gives organizations a single entry point for all agent and model traffic. You register any MCP servers your organization uses, whether from Databricks or any other vendor, and all agent requests flow through the gateway. From there, you can set spend budgets at group, subgroup or individual level, with automatic rate-limiting or alerts when limits are hit.
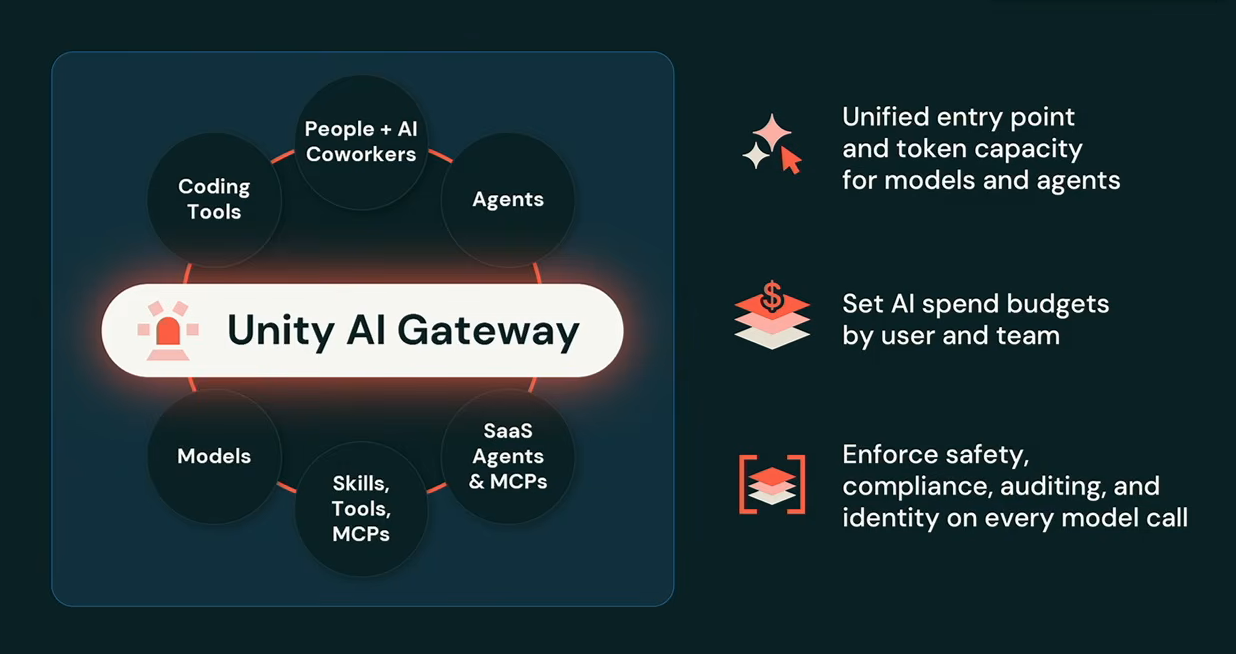
Architecture diagram of Databricks Unity AI Gateway, as presented by Ali Ghodsi at Databricks Data + AI Summit 2026 (Source: Databricks Data + AI Summit 2026)
Every dollar committed to Databricks can be applied toward tokens from OpenAI, Anthropic or Google Gemini models, across AWS, Azure or Google Cloud Platform. The gateway also handles authentication across all MCP servers, safety filtering, compliance and auditing. Frontier models now turn over roughly every month. Unity AI Gateway means you swap the underlying model through configuration rather than rewriting applications. Unity AI Gateway is open sourced as part of both Unity Catalog and MLflow.
OpenSharing
Though announced publicly on June 10, five days before the summit opened, OpenSharing featured prominently in the Day 1 narrative. OpenSharing is a new open, vendor-neutral protocol hosted by the Linux Foundation and it’s the next evolution of Delta Sharing, the open data-sharing protocol Databricks contributed to the community in 2021.

Databricks OpenSharing protocol overview (Source: Databricks) – Databricks Data + AI Summit 2026
Where Delta Sharing covered structured tabular data, OpenSharing extends the protocol in three directions: it supports sharing AI assets (agent skills, trained model artifacts), it adds support for Apache Iceberg REST-compatible clients to expand the recipient ecosystem and it enables on-premises and private-cloud data sources to connect directly to cloud platforms without data movement. The protocol already has 28,000+ data recipients, with 33 percent of shares flowing across platforms via open connectors.
Genie Ontology
With the data and governance foundation in place, Ghodsi shifted to what he called one of the most important announcements of the summit.
The problem he laid out: current agentic systems do a live, looping traversal of your data every time a question comes in. An agent opens a document, reads it, follows a link, calls an MCP server, reads another document and continues the loop until it has enough context to answer. This is slow, expensive and produces inconsistent results because the agent is doing a random walk through a small subset of a massive corpus.
Genie Ontology is the answer. It runs continuously in the background, building a knowledge graph of organizational context before anyone asks a question. It connects to the lakehouse, Unity Catalog, Google Drive, SharePoint, email, Jira, Slack, Confluence and more than 50 connected systems.
The ranking algorithm driving it is called OntoRank, which Ghodsi compared to PageRank. OntoRank does a similar thing but across heterogeneous enterprise asset types like source code, documents, structured tables, unstructured files. It also incorporates the organizational graph like who in the company accesses what, how frequently and what role they have in the org chart.

Databricks Genie Ontology overview, as presented by Ali Ghodsi at Databricks Data + AI Summit 2026 (Source: Databricks Data + AI Summit 2026)
The result is that agents can retrieve the right context in milliseconds rather than minutes, because the graph-building work has already been done.
Genie Ontology also connects to existing semantic layers: Unity Catalog metric views, business glossaries and semantic layers from third-party BI tools all feed into it. Human-curated definitions and automatically generated ontology work together.
Unity Catalog shipped three new semantic capabilities at the summit to support this foundation:
- Business Glossary (Preview coming soon): Authoritative definitions for business concepts, connected to underlying data assets and co-curated by humans and Genie Code
- Domains (Public Preview): Organize data and AI assets into business-aligned categories so agents receive scoped context rather than the entire catalog
- Metrics (core features in Public Preview): Define KPIs once as governed objects, reusable across dashboards, agents and apps; supports multi-fact relationships, parameterization and materialization
All three feed directly into Genie Ontology. The richer your semantics layer in Unity Catalog, the better Genie’s answers.
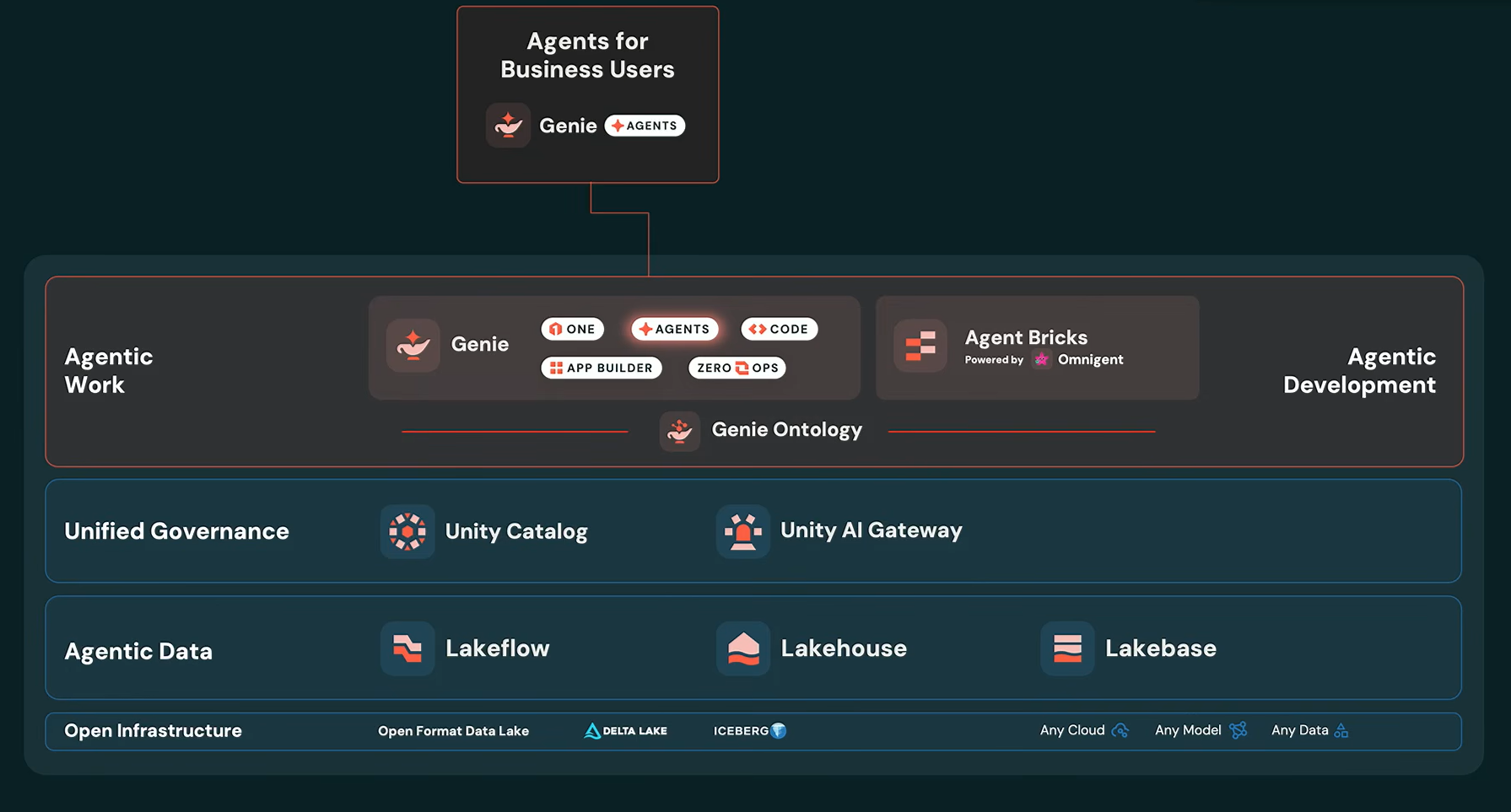
The new Genie agents: Genie One, Genie Agents, Genie Code, Genie ZeroOps and Genie App Builder
Ali Ghodsi announced a suite of new Genie agents, all powered by Genie Ontology.
Genie One
Genie One is the new unified interface for business users, a break from the previous Genie, which was scoped to specific domains. “This is not that Genie. This is Genie One”, he said.

Ali Ghodsi announcing Databricks Genie One at Databricks Data + AI Summit 2026
Genie One connects business teams to data across the Databricks lakehouse, Google Drive, SharePoint, Salesforce, Jira and more, through more than 50 connected apps at launch.
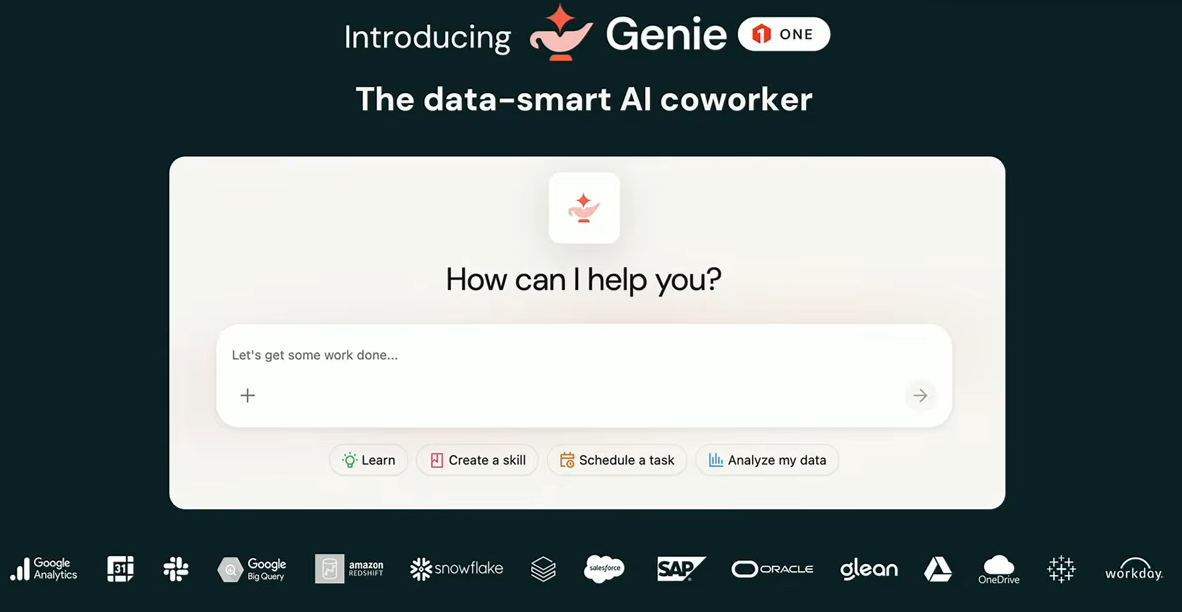
Databricks Genie One overview, as presented by Ali Ghodsi at Databricks Data + AI Summit 2026 (Source: Databricks Data + AI Summit 2026)
It goes well beyond answering questions. Genie One can produce documents, reports and artifacts, run scheduled tasks, set alerts and take action through MCP tool integrations. It’s generally available on web, iOS and Android.
Genie Agents
Genie Agents extend Genie One.
Databricks Genie Agents overview, as presented by Ali Ghodsi at Databricks Data + AI Summit 2026 (Source: Databricks Data + AI Summit 2026)
Users can take an existing Genie One conversation and save it as a reusable agent, which inherits the conversation’s memory, sources, instructions and behavior. Those agents can be shared across the organization and embedded in Slack or Microsoft Teams. The agents can perform autonomous work, including gathering information from Salesforce, updating records in Workday, generating reports and coordinating with other agents.
Genie Code
Genie Code is the technical counterpart, aimed at data engineers and ML teams.
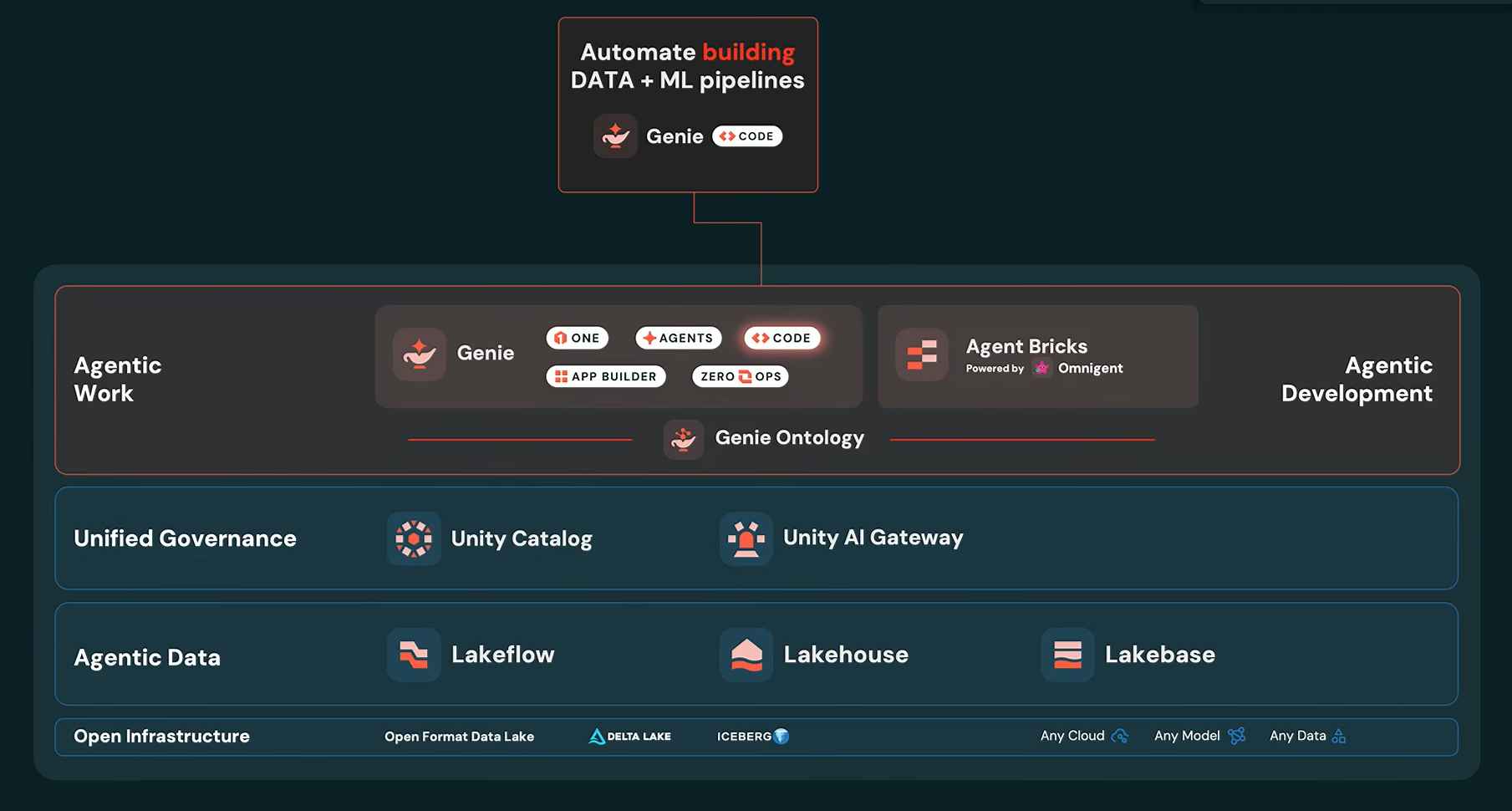
Databricks Genie Code overview, as presented by Ali Ghodsi at Databricks Data + AI Summit 2026 (Source: Databricks Data + AI Summit 2026)
It draws on Genie Ontology’s organizational context to understand how teams build features, train models and manage production pipelines, so it behaves more like an experienced data engineer than a generic coding assistant. A new full-page command center lets teams manage multiple parallel Genie Code threads simultaneously.
Genie ZeroOps
Among the new launches, Ghodsi reserved some of his strongest praise for Genie ZeroOps.
Ali Ghodsi announcing Databricks Genie ZeroOps at Databricks Data + AI Summit 2026
Genie ZeroOps is an autonomous background monitoring agent that continuously watches pipelines, ML models and other data assets for operational issues. When a problem occurs, it investigates the root cause, proposes a fix and tests that fix in an isolated environment before presenting the recommendation for human approval. Nothing touches production without explicit human sign-off.
“No one wants to wake up at 2 am”, Ghodsi said.
Genie App Builder
The final piece of the Genie strategy is Genie App Builder, which expands the platform from agents and automation into application development.
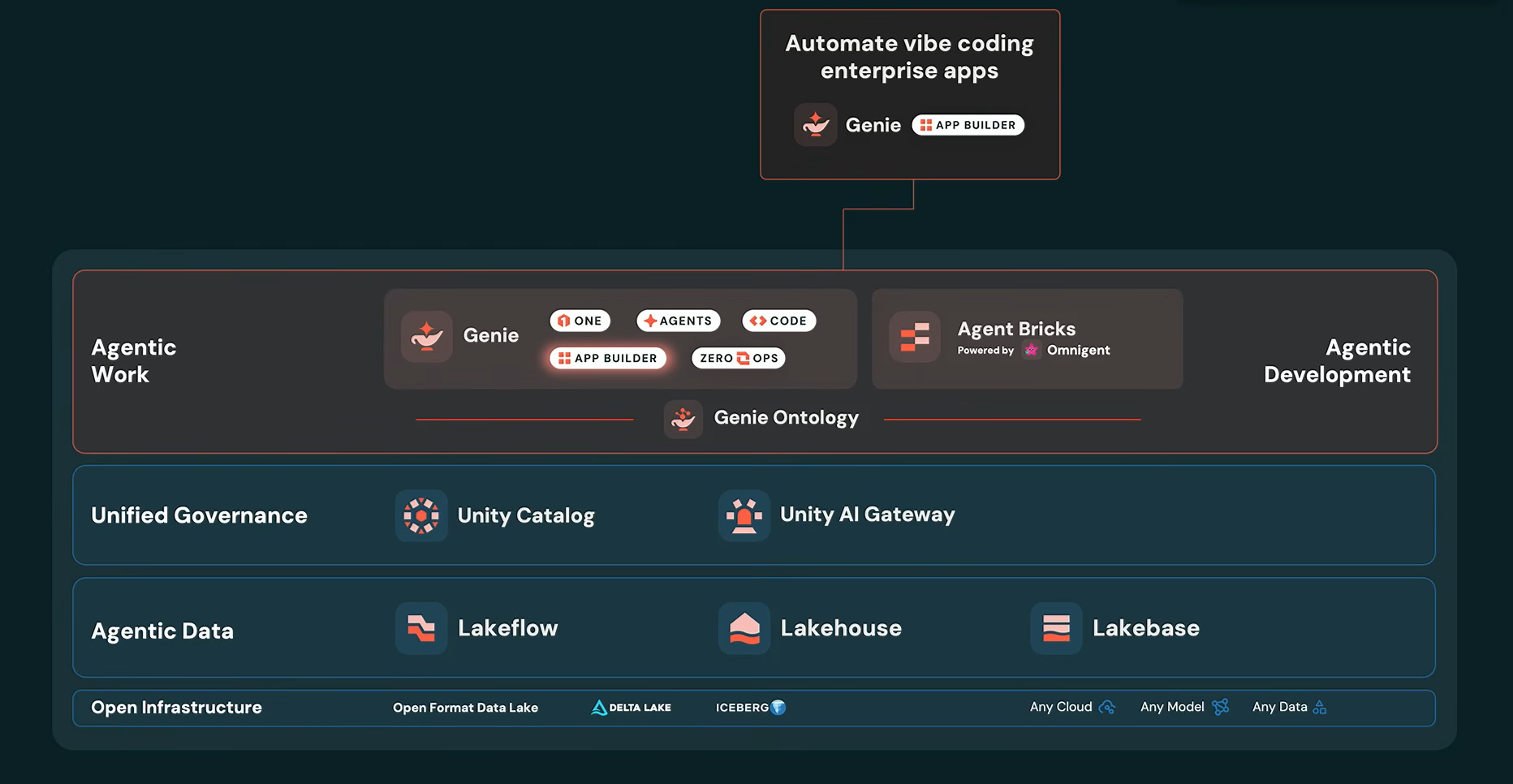
Databricks Genie App Builder, as presented by Ali Ghodsi at Databricks Data + AI Summit 2026 (Source:Databricks Data + AI Summit 2026)
Genie App Builder is designed to let organizations quickly build data and AI applications that sit on top of enterprise data, governance controls and the full Genie context layer, without stitching together multiple services.
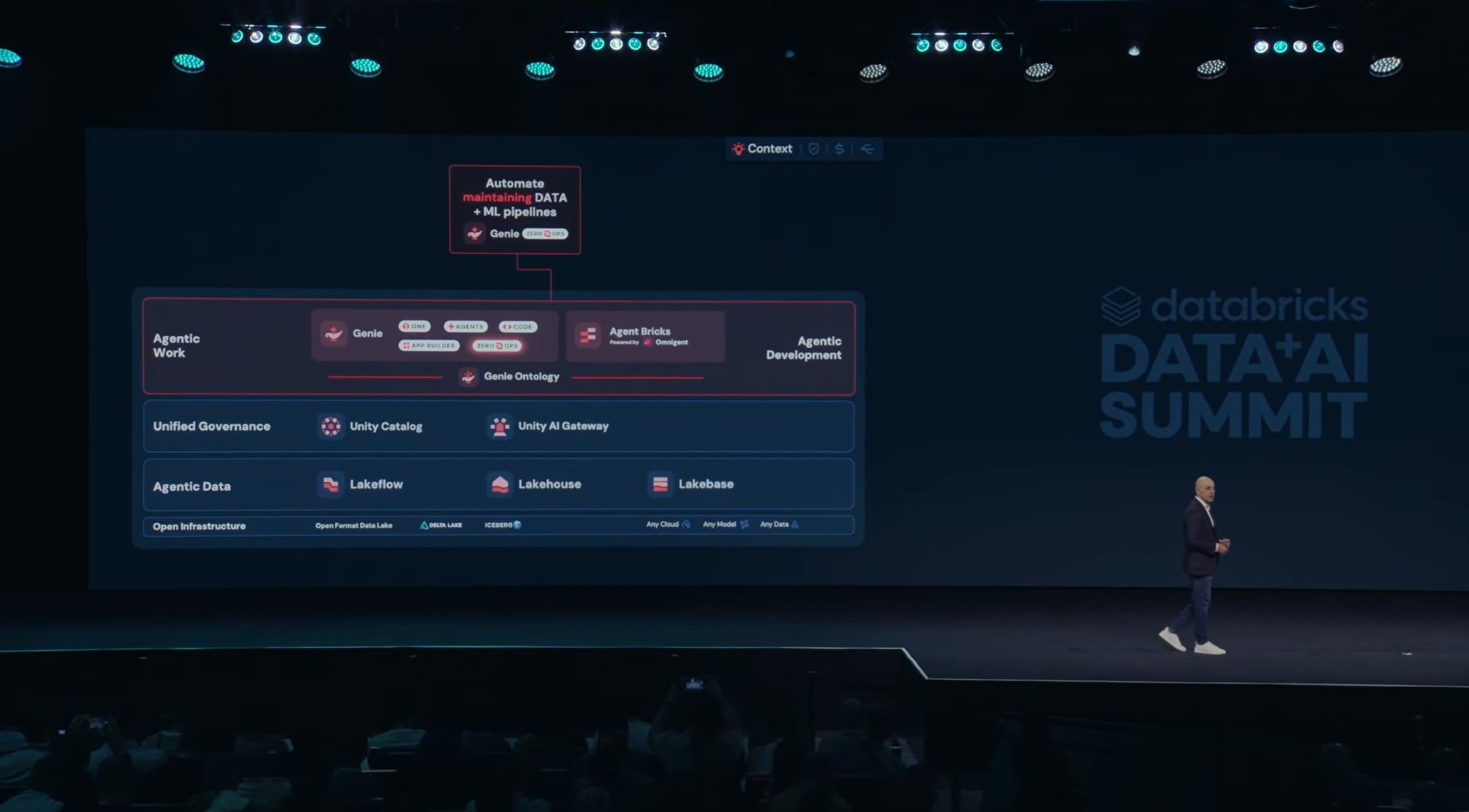
Agent Bricks and Omnigent
For developers building lower-level agentic systems, Ghodsi announced an expanded Agent Bricks platform with fast sandboxes for isolated agent execution and added agent memory. The underlying idea is that developers are already using tools like Claude Code and Codex, so Databricks wants to be the platform underneath all of that, not a replacement for any single harness.
Which brings us to the most interesting part of the Agent Bricks announcement called Omnigent. It is a meta harness that sits above all the individual coding frameworks. Instead of forcing organizations to commit to one framework, Omnigent can compose multiple frameworks, apply centralized governance and run different approaches against the same problem to surface the best result. You can swap or combine harnesses with one-line changes, set cost budgets and contextual policies, and share live agent sessions via URL.
Matei Zaharia covers the full architecture in the Day 2 section below.
Databricks Agent Bricks and Omnigent announcement, as presented by Ali Ghodsi at Databricks Data + AI Summit 2026 (Source:Databricks Data + AI Summit 2026)
The SaaS stack problem
Before the security announcements, Ghodsi laid out the architectural motivation behind the entire product direction. Traditional SaaS architecture gives each business domain its own system of record with its own AI agent. The problem: real business questions involve multiple systems, from HR to CRM to finance. Since vendors are competing for the same budget, they have little incentive to share data cleanly.
His proposed solution is what he called an “agentic system of record”, a unified data and AI platform where agents can access everything in one governed, open format environment with cost controls built in.
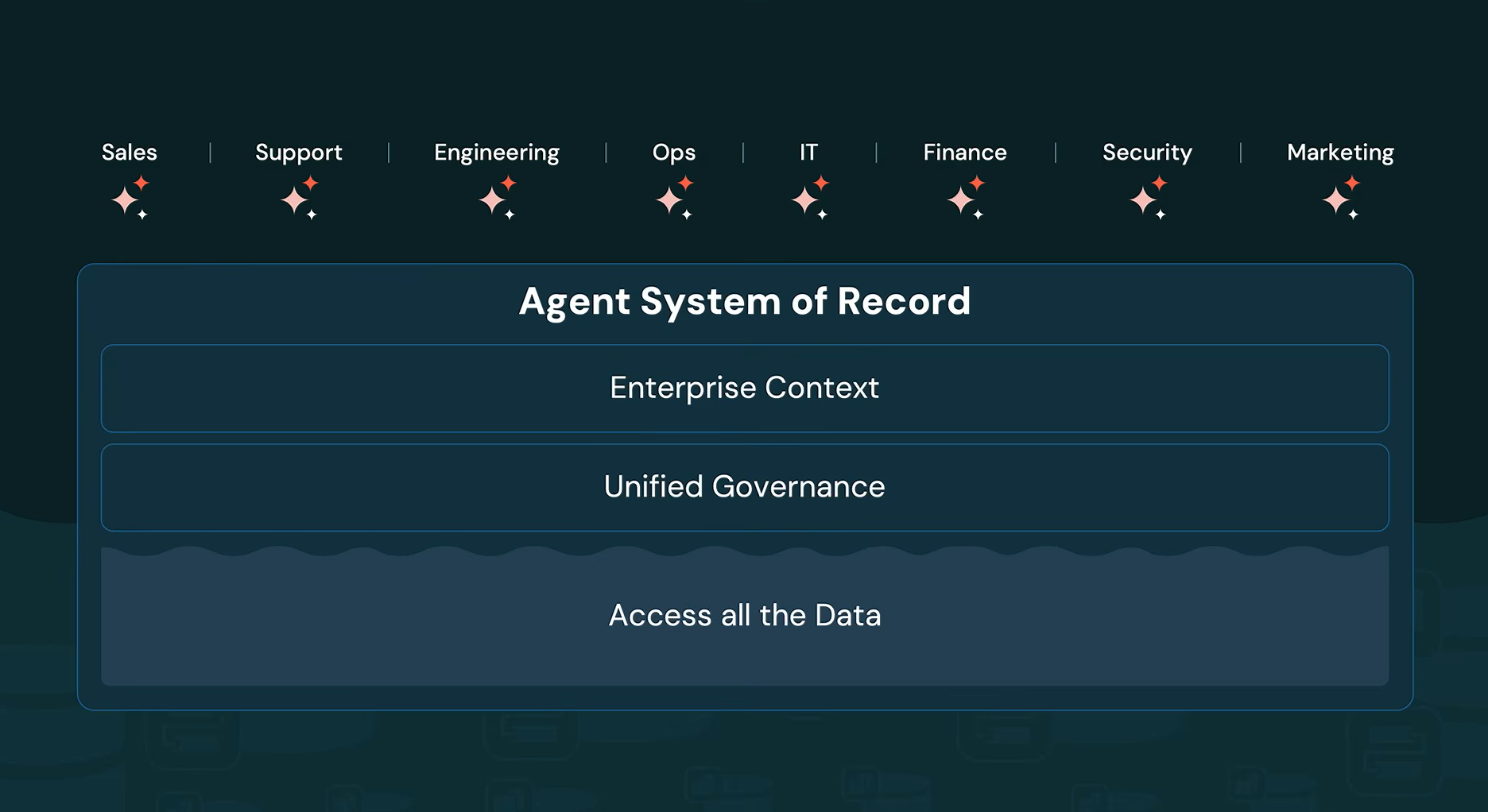
Agentic system of record architecture diagram, as presented by Ali Ghodsi at Databricks Data + AI Summit 2026 (Source:Databricks Data + AI Summit 2026)
Lakewatch and the Panther Labs acquisition
On the security side, Ghodsi detailed Lakewatch, Databricks’ agentic SIEM built on the lakehouse. Lakewatch was first announced in April 2026, when Databricks entered the cybersecurity market at RSA Conference 2026. The core problem it solves is economics: traditional SIEMs are expensive to ingest data into, so security teams end up pre-filtering what goes in. That filtering creates coverage gaps that are growing more dangerous as agentic attacks accelerate.

Ali Ghodsi announcing Databricks Lakewatch at Databricks Data + AI Summit 2026
Lakewatch stores all security data in open source lakehouse format, then runs agents on top to handle detection creation, alert triage for SOC analysts and proactive threat hunting for zero-day attacks. It natively supports the open cybersecurity schema framework (OCSF) and promises up to 80 percent lower total cost of ownership compared to legacy SIEMs.
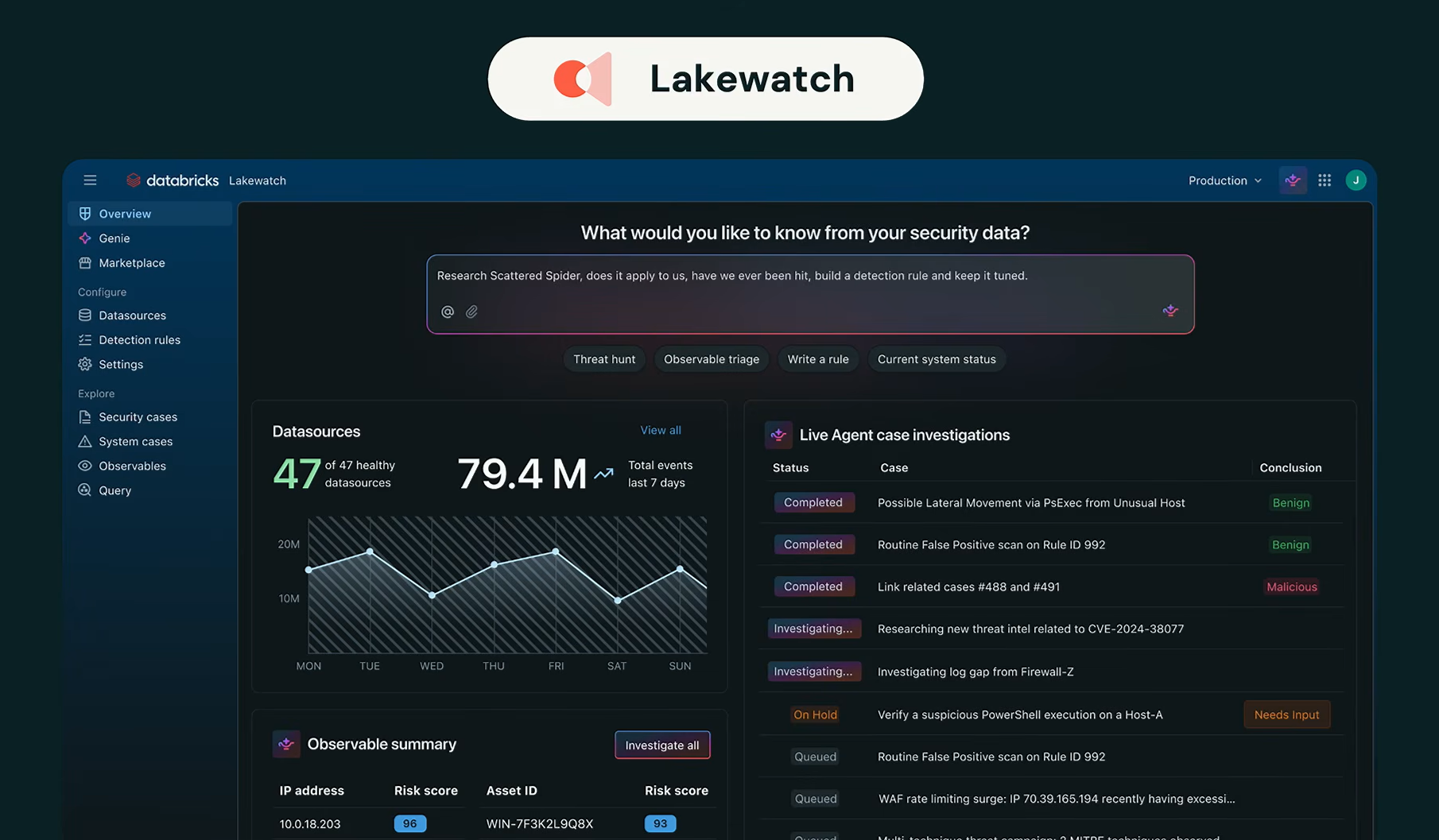
Databricks Lakewatch overview, as presented by Ali Ghodsi at Databricks Data + AI Summit 2026 (Source:Databricks Data + AI Summit 2026)
Tied directly to this, Ghodsi announced that Databricks has agreed to acquire Panther, a cloud-native AI SOC platform founded by Jack Naglieri. Panther was built on the StreamAlert open source project that Naglieri’s team originally created at Airbnb after finding traditional SIEMs too slow and expensive at scale. Panther has since evolved into a cloud-native SIEM and AI SOC platform built on detection-as-code and security data lakes. Anthropic is among its customers.

Ali Ghodsi announcing Databricks + Panther acquisitions at Databricks Data + AI Summit 2026
Panther brings more than 100 out-of-the-box security integrations covering cloud infrastructure, identity providers, endpoints, networks and SaaS applications, plus detection-as-code capabilities and agentic SOC workflows.
CustomerLake
Ghodsi also introduced CustomerLake, an agentic customer data platform (CDP) built on the lakehouse.

Databricks CustomerLake overview, as presented by Ali Ghodsi at Databricks Data + AI Summit 2026 (Source: Databricks Data + AI Summit 2026)
CustomerLake ships with two AI-powered modules. A Profile Agent handles identity deduplication using LLMs, combining AI-generated matching rules, large language models and human review to identify duplicate customer records. Databricks says this produces more accurate results than traditional rule-based or ML-based identity matching. A Campaign Agent powers what Databricks calls “Infinity Campaigns”, moving marketing away from audience segmentation buckets toward true one-to-one personalization made cost-effective by small, distilled LLMs. Each customer gets their own agent that reads the latest signals, determines the next best action and generates personalized content in a continuous loop.
And that wraps up the first half of Ghodsi’s Day 1 keynote. The rest of Day 1 brought separate speakers for deeper product dives.
Why today’s AI agents fail at enterprise data and what Genie One does about it
Ken Wong, senior director of product management for Genie and AI/BI at Databricks, opened the second half of the keynote by justifying why Genie One was necessary.

Ken Wong introducing Genie One and Genie Ontology at Databricks Data + AI Summit 2026
Wong shared the results of tests he ran ahead of a product advisory board meeting. He asked Genie One to build a comprehensive customer profile from email, Slack, calendar, Salesforce and Databricks consumption data. The result was solid and visualized cleanly.
Ken Wong introducing Genie One and Genie Ontology at Databricks Data + AI Summit 2026
When he ran the same prompt with other leading AI assistants and coding agents, results were poor. One fabricated numbers and admitted it. Another used stale data. Coding agents took too long, hit limits, or produced incomplete work.
Databricks’ internal research found that coding agents solved real employee questions about Genie usage only about half the time, and each attempt took minutes. “50% of the time for a real data question is basically unusable”, Wong said.
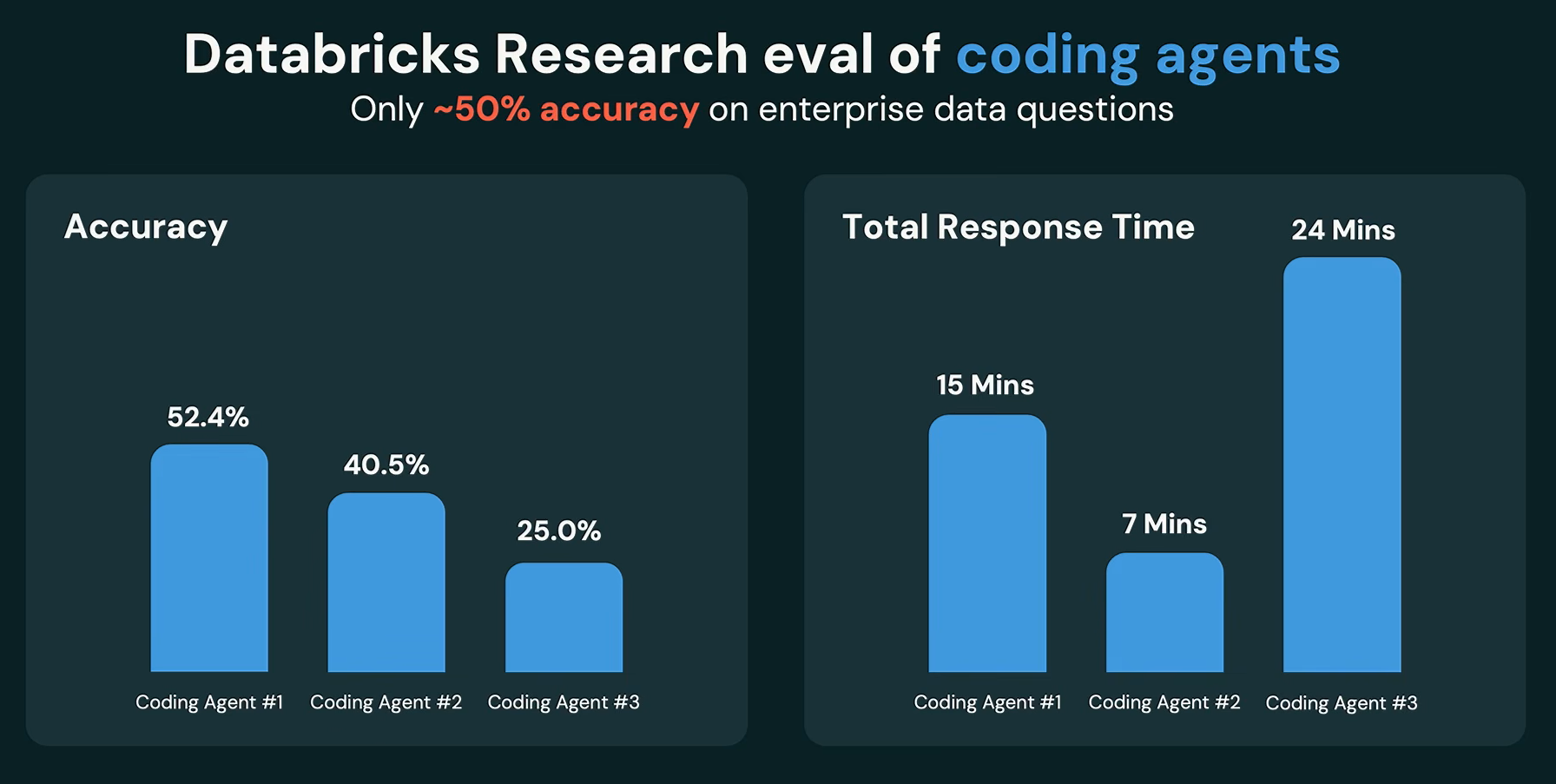
Databricks research eval of coding agents, as presented by Ken Wong at Databricks Data + AI Summit 2026 (Source:Databricks Data + AI Summit 2026)
The solution he shared was Genie Ontology, an automatic context layer on top of your models. It extracts knowledge from pipelines, queries, dashboards and more, ranks authoritative knowledge snippets with OntoRank, applies permissions and injects relevant context into the agent loop.
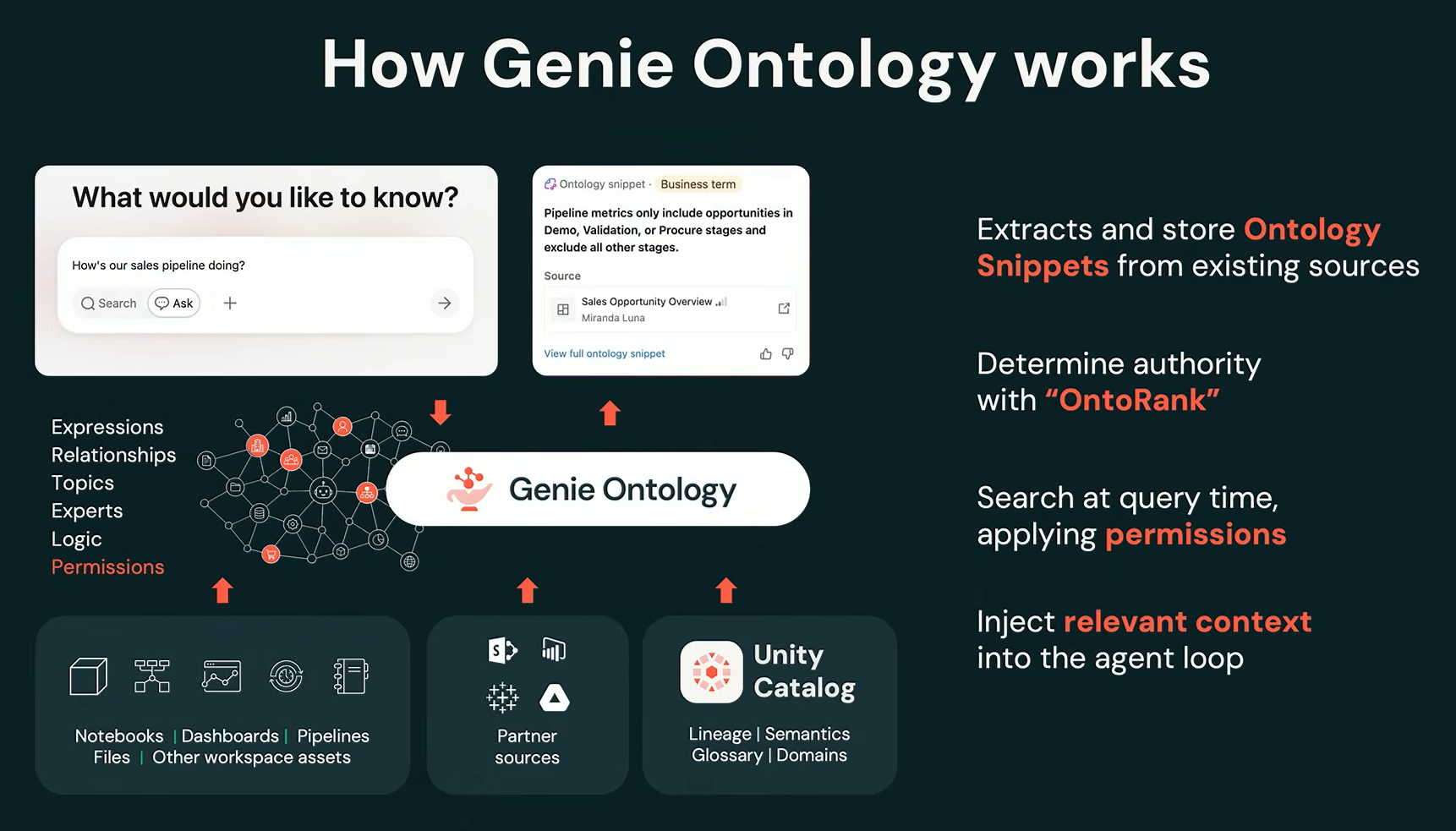
Databricks Genie Ontology architecture, as presented by Ken Wong at Databricks Data + AI Summit 2026 (Source:Databricks Data + AI Summit 2026)
Wong showed that this improved accuracy to 84.5% while cutting runtime by approximately half compared with leading coding agents.
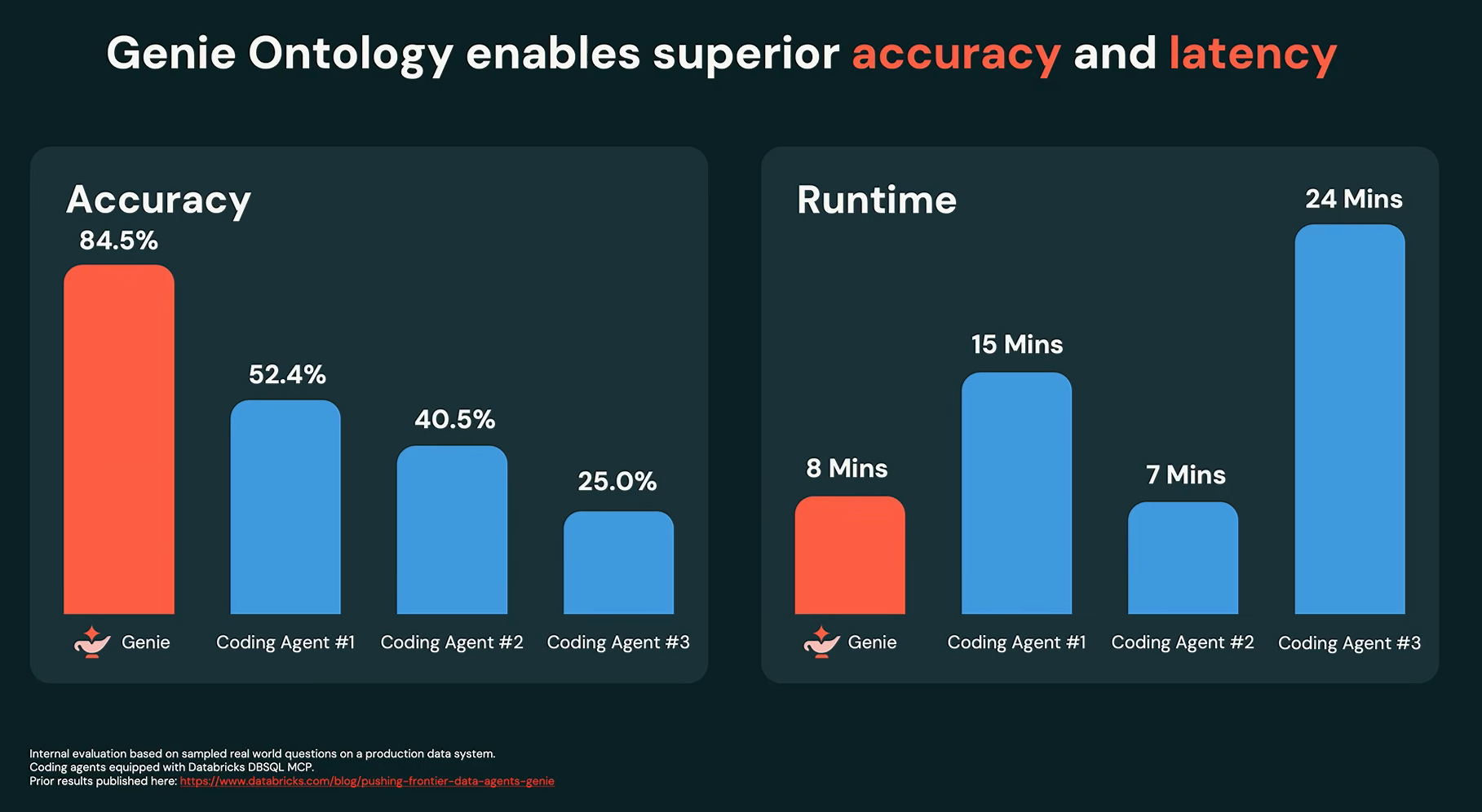
Genie Ontology accuracy and latency overview, as presented by Ken Wong at Databricks Data + AI Summit 2026 (Source:Databricks Data + AI Summit 2026)
“With this level of accuracy enabled by the Genie Ontology, now we can truly create a data-smart co-worker”, he said.
Genie One live demo
Elise Georis, product manager for Genie at Databricks, gave a live demo showing what that looks like in practice.

Elise Georis keynote at Databricks Data + AI Summit 2026 – Databricks Summit 2026
In the demo, Genie prepared an executive OKR review by pulling information from Unity Catalog, Jira, Google files, BigQuery and Databricks data sources. Instead of just summarizing existing documents, Genie executed SQL queries against live operational data to calculate current metrics and generate visualizations.

Elise Georis demonstrating Genie One live at Databricks Data + AI Summit 2026
The demo highlighted several specific capabilities:
- Creating documents from live data computation, not static summaries
- Executing actions through Model Context Protocol (MCP) tools, including updating Jira tickets
- Building domain-specific agents from existing conversations
- Scheduling recurring workflows
- Providing citations showing exactly which data sources and knowledge snippets drove each answer
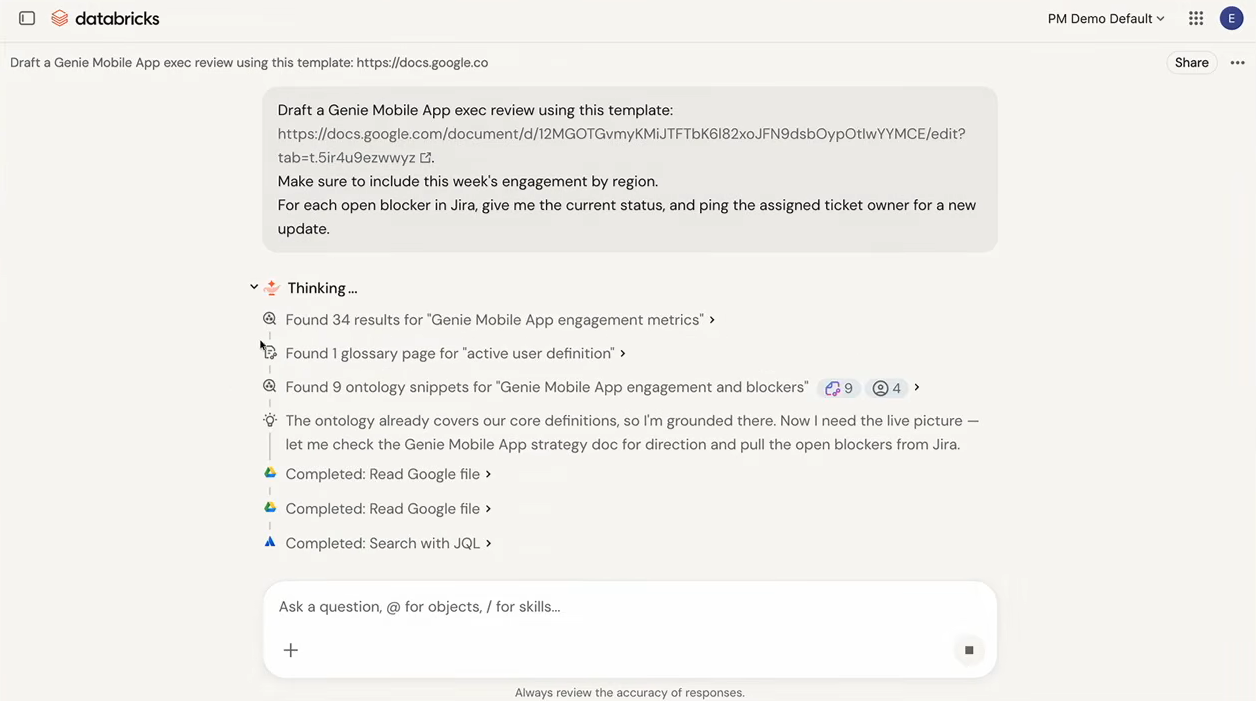
Databricks Genie demo:, as presented by Elise Georis at Databricks Data + AI Summit 2026 (Source: Databricks Data + AI Summit 2026)
Georis emphasized that Genie follows Unity Catalog permissions automatically. No separate security model is required. During the mobile portion of the demo, Genie proactively alerted Georis about an unexpected spike in mobile app engagement without a monitoring rule being set up beforehand. That’s ZeroOps behavior at the consumer layer.
Wong closed the Genie One section with availability details. Genie One is generally available on web, iOS and Android. It’s available in Microsoft Teams and Slack. And Databricks is giving every user $10 in free tokens per month to reduce friction from getting started.
PepsiCo explains how it turned data infrastructure into an AI foundation
Magesh Bagavathi, global chief data and AI officer at PepsiCo, joined Arsalan Tavakoli-Shiraji, Databricks co-founder and SVP of field engineering, for a fireside conversation.

Global Chief Data and AI Officer at PepsiCo Magesh Bagavathi in conversation with Databricks co-founder Arsalan Tavakoli – Databricks Data + AI Summit 2026 – Databricks Summit 2026
Bagavathi explained that PepsiCo’s transformation started roughly six years ago. The company consolidated more than 60 separate data lakes into a unified lakehouse on Databricks, bringing about 90% of its enterprise data onto a single platform. He described the scale behind that:
- More than 320,000 employees globally
- Operations across approximately 200 countries
- Around 1.4 billion consumer occasions every day
- More than 6 million retail touchpoints
PepsiCo also shared early results from deploying Genie inside its SpendWise procurement platform. The company recorded nearly 30,000 interactions in the first few weeks and observed users shifting away from traditional dashboards toward conversational data experiences.
“It’s not real until you productionize it”, Bagavathi said. PepsiCo’s long-term goal is to move from thousands of reports toward AI-driven business consoles that can surface insights and eventually take actions.
LakeFlow aims to simplify the modern data engineering stack
Bilal Aslam, senior director of product management for LakeFlow, took the stage to address the growing pressure on data engineering teams as AI agents create demand for more pipelines, more real-time data and greater operational complexity.

Bilal Aslam presenting LakeFlow updates and new capabilities at Databricks Data + AI Summit 2026 – Databricks Summit 2026
His argument: AI applications are only as good as the pipelines that feed them.
Databricks presented LakeFlow as a unified data engineering foundation built around open formats and open frameworks.
Key LakeFlow announcements
Spark Declarative Pipelines with real-time streaming
Databricks expanded Spark Declarative Pipelines to combine batch and streaming workloads using SQL and Python. Real-Time Mode integrates millisecond-level streaming into the same programming model, eliminating the need for a separate engine like Apache Flink for low-latency use cases.

Bilal Aslam announcing Spark Declarative Pipelines at Databricks Data + AI Summit 2026
LakeFlow Designer
LakeFlow Designer became generally available. It generates Spark Declarative Pipelines underneath a drag-and-drop canvas, so business analysts can build production ETL pipelines in natural language without writing code, while data engineers can review and refine the generated Spark code directly in place.
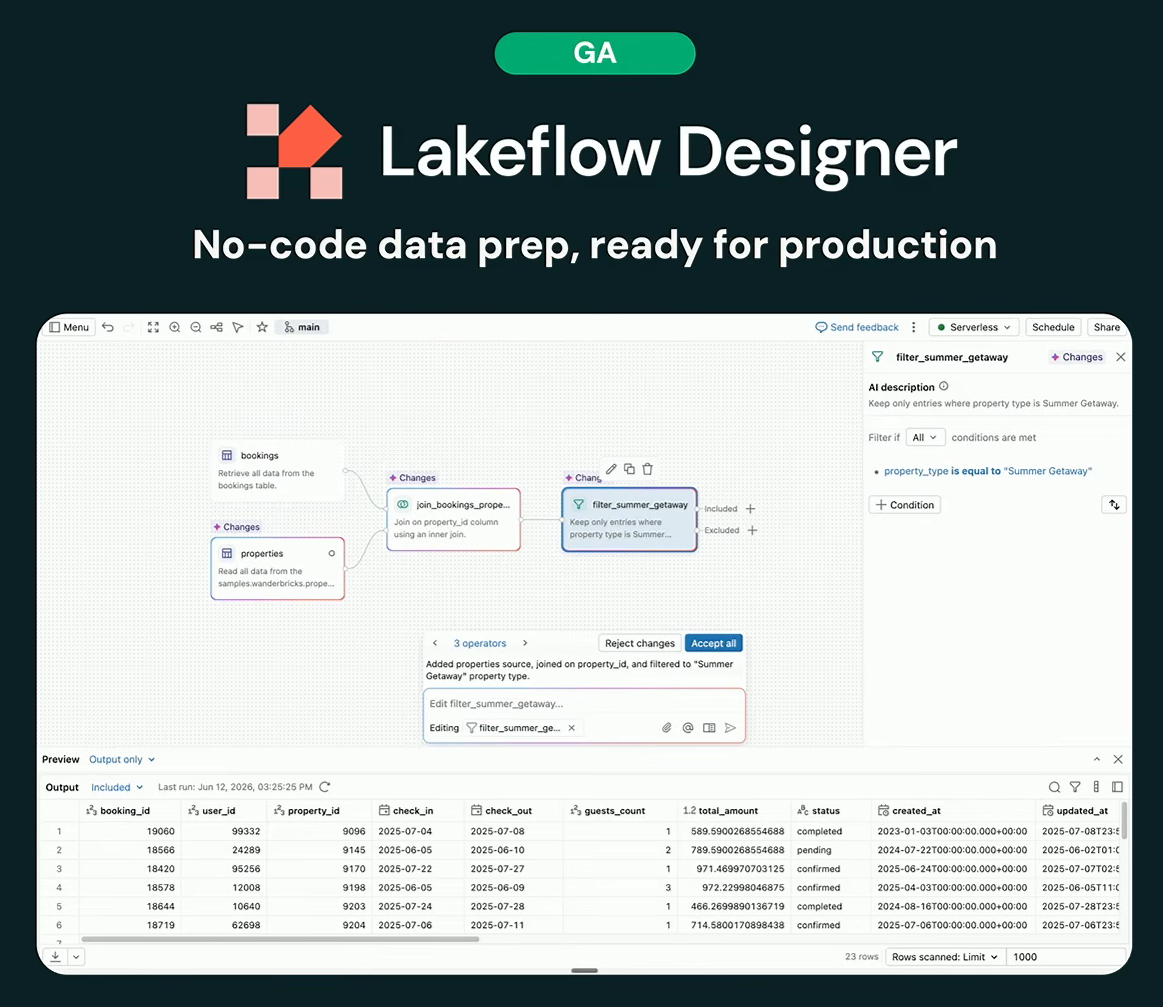
Databricks Lakeflow Designer, as presented by Bilal Aslam at Databricks Data + AI Summit 2026 (Source: Databricks Data + AI Summit 2026)
LakeFlow Connect: 100+ connectors
LakeFlow Connect now has more than 100 connectors, including community-developed connectors and options for customers to build their own. Like everything else in LakeFlow, these run as Spark Declarative Pipelines underneath.
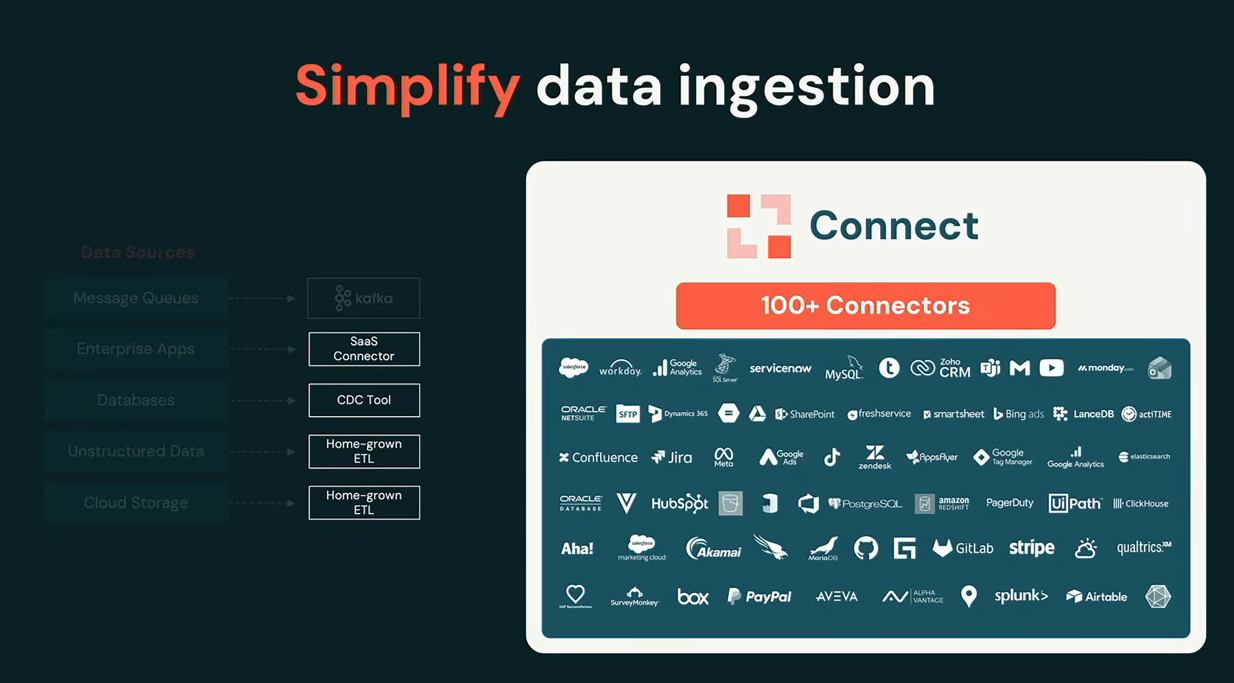
Databricks Lakeflow connect new connectors:, as presented by Bilal Aslam at Databricks Data + AI Summit 2026 (Source:Databricks Data + AI Summit 2026)
ZeroBus Ingest: Kafka without the Kafka
For high-volume telemetry and event data, Databricks announced ZeroBus Ingest. ZeroBus Ingest is a fully managed service that is compatible with the Kafka wire protocol via its Kafka-Compatible APIs (in beta), so existing Kafka producers can point at ZeroBus with no code changes. It delivers sub-5-second latency with over 10 GB/s of aggregate throughput to a single table, writing directly to open Delta tables with no message broker to manage and no small files to compact.

Bilal Aslam announcing Zerobus ingest at Databricks Data + AI Summit 2026
LakeFlow Jobs: 50+ new integrations
LakeFlow Jobs, which supports Python-based workflow authoring and point-and-click directed acyclic graph (DAG) building, added more than 50 integrations for orchestrating external systems. Aslam called this one of his favorite announcements at the summit.
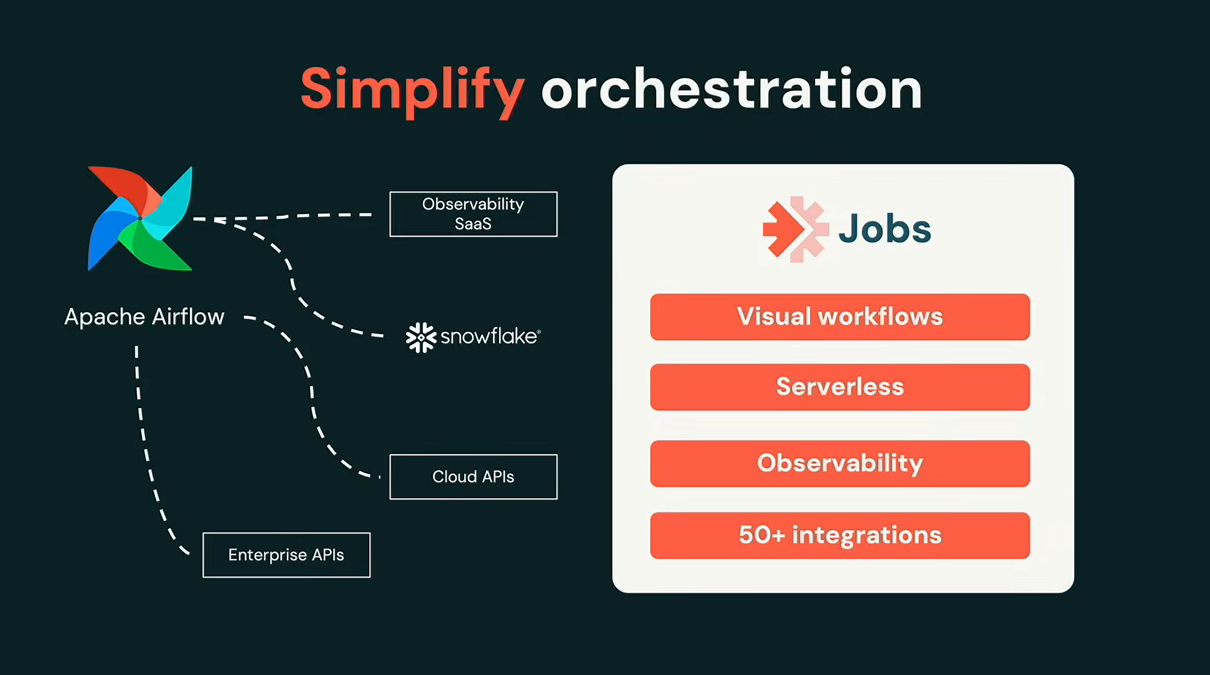
Databricks Lakeflow Jobs overview, as presented by Bilal Aslam at Databricks Data + AI Summit 2026 (Source: Databricks Data + AI Summit 2026)
Aslam shared usage statistics: Spark Declarative Pipelines process 200 trillion rows of data every day. LakeFlow Jobs runs 1.7 billion job runs per month. And 50 percent of Databricks customers have opted into serverless compute.

Databricks LakeFlow usage statistics, as presented by Bilal Aslam at Databricks Data + AI Summit 2026 (Source:Databricks Data + AI Summit 2026)
Genie ZeroOps
The second major announcement from Aslam was Genie ZeroOps, a new background agent that puts data and AI operations on autopilot. This is where he addressed the harder problem. Building pipelines is one thing. Keeping them running is another.
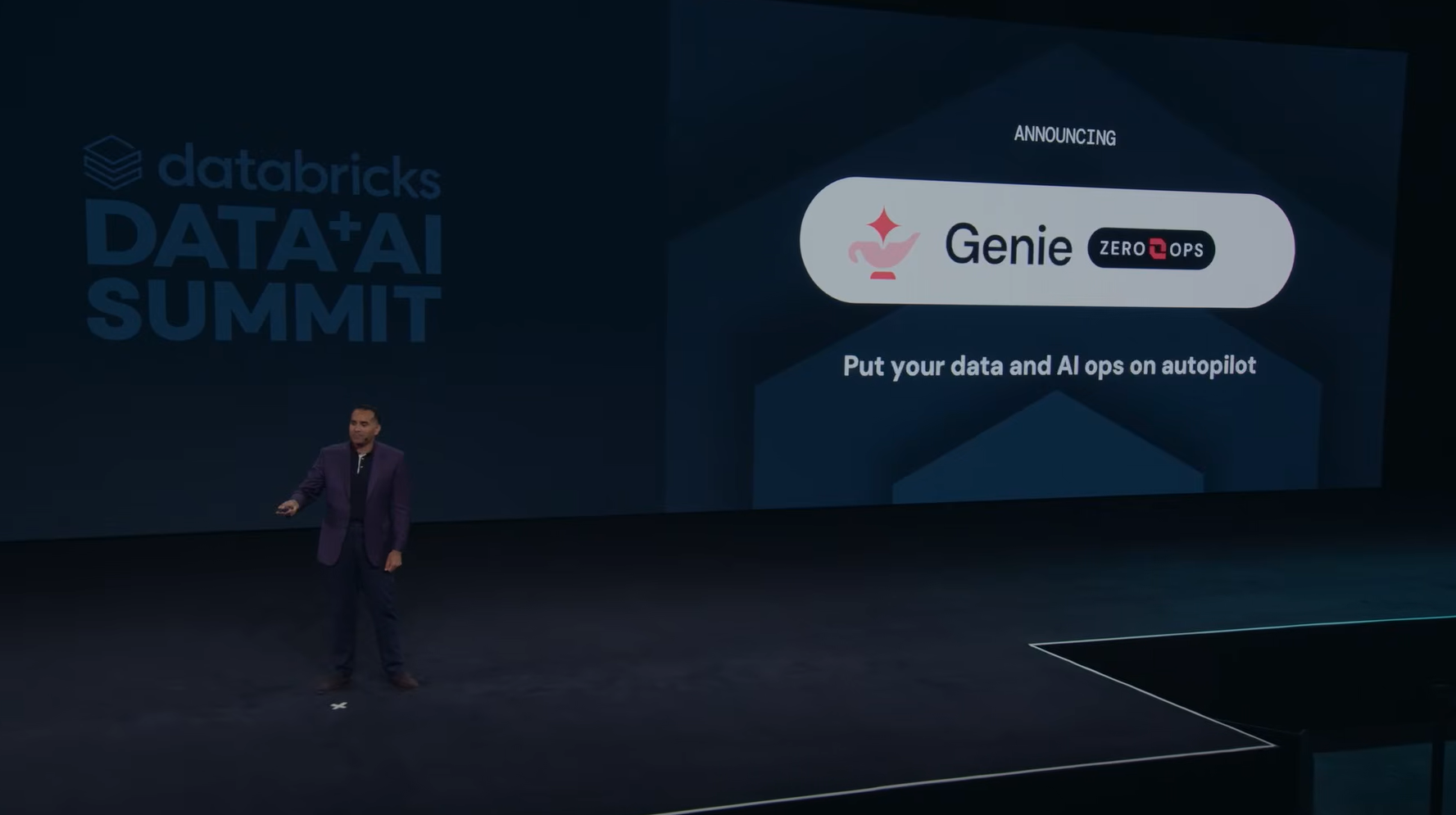
Bilal Aslam introducing Genie ZeroOps at Databricks Data + AI Summit 2026
Here’s how Genie ZeroOps works:

Bilal Aslam explaining how ZeroOps works at Databricks Data + AI Summit 2026
Detection. Genie ZeroOps autonomously builds per-table machine learning models, continuously fine-tuning them with native access to metrics, events and logs. Databricks already has tens of thousands of these models in production.
Impact assessment. It does graph ranking on data lineage in Unity Catalog, walking the lineage forward to understand which downstream tables and dashboards depend on the affected table and flagging critical assets.
Root cause analysis. A supervisor agent deploys a fleet of sub-agents to investigate potential causes upstream, walking lineage backwards and converging on the most likely explanation.
Remediation. ZeroOps works with Genie Code to update tickets and draft fixes as it moves through the investigation.
Verification. The hardest step. Genie ZeroOps creates shallow clones of production data using the same branching mechanism as Lakebase, deploys the proposed fix to the clone, verifies the row counts and presents the fix as a pull request. Nothing touches production without your explicit approval.
Aslam then gave a clear overview of ZeroOps in action and wrapped up his session for Day 1.
The last gap in the data stack
Ghodsi returned briefly to frame the next announcements. He described what he called “the known data realm”, a map of data infrastructure with two major continents.
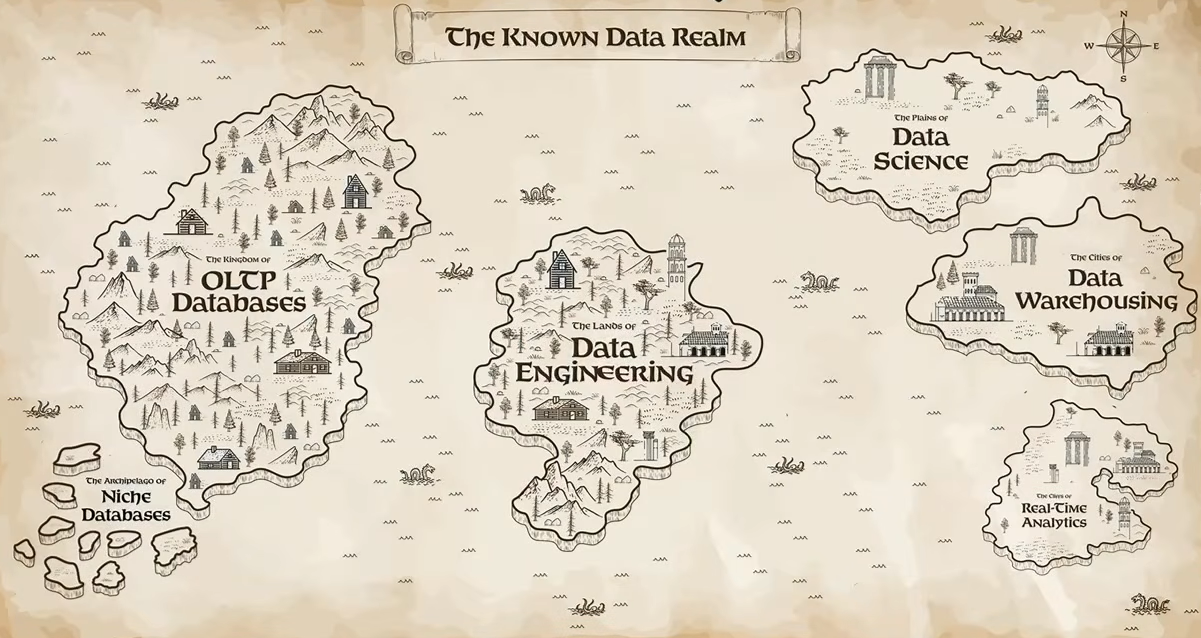
The ‘Known data realm’ overview, as presented by Ali Ghodsi at Databricks Data + AI Summit 2026 (Source: Databricks Data + AI Summit 2026)
On one side: online transaction processing (OLTP) databases, built in the 1980s to power fast, reliable transactional applications. On the other: data warehouses and analytics platforms, which emerged to analyze large volumes of data without affecting operational systems. Over time, data science and real-time analytics each developed their own separate infrastructure.
Ghodsi argued that the rise of AI agents is putting even more pressure on this fragmented architecture. As organizations deploy more agents, the number of queries, data interactions and dependencies will increase significantly.
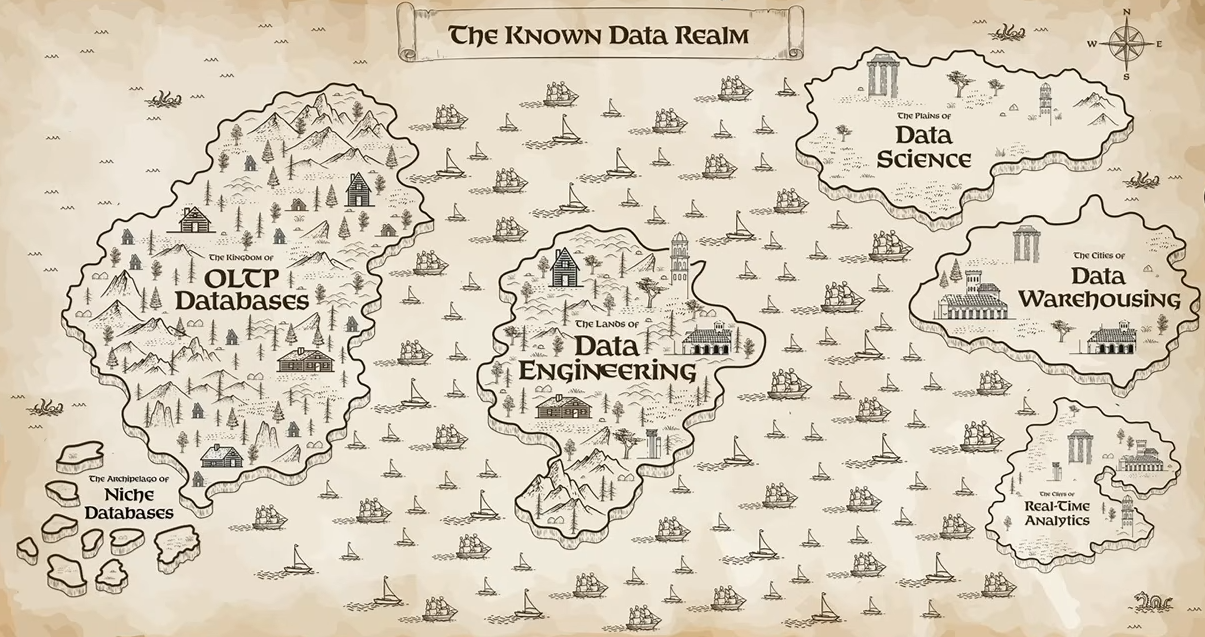
The ‘Known data realm’ overview, as presented by Ali Ghodsi at Databricks Data + AI Summit 2026 (Source: Databricks Data + AI Summit 2026)
He pointed out that Databricks had already brought together data engineering, data science and data warehousing under the lakehouse architecture. However, one major challenge remained: real-time analytics.
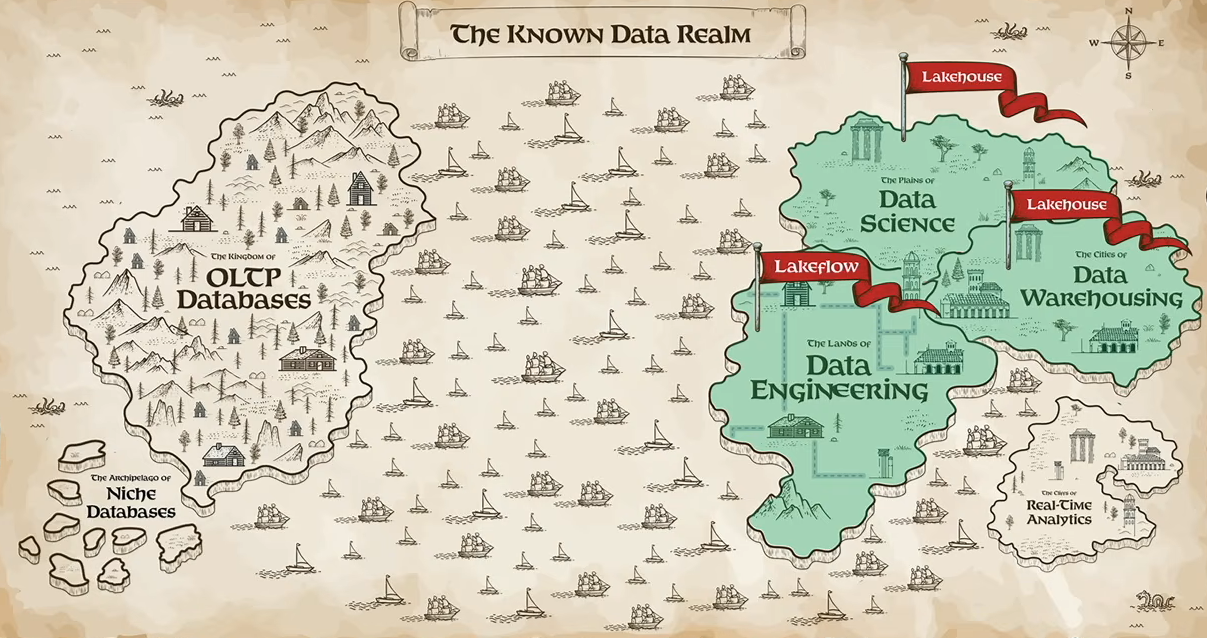
The ‘Known data realm’ overview, as presented by Ali Ghodsi at Databricks Data + AI Summit 2026 (Source: Databricks Data + AI Summit 2026)
With that setup, Ghodsi handed the stage over to Reynold Xin to introduce Databricks’ next major announcement focused on closing that final gap.
Reynold Xin on Lakehouse\\RT and the Reyden engine
Reynold Xin, co-founder of Databricks, joined the stage and called this announcement “probably the largest single innovation we have done since our introduction of lakehouse”.

Reynold Xin keynote at Databricks Data + AI Summit 2026 – Databricks Summit 2026
The issue he was solving: despite years of performance improvements, lakehouses and data warehouses hit a wall at roughly one second of consistent latency. For workloads with tight service-level agreements in the millisecond range, latency spikes make that impossible to guarantee. So organizations build separate serving stacks, copy data into them and end up with pipeline maintenance overhead, broken governance and a serving layer that only handles simple queries.
Xin’s question: “What if you never had to move your data? What if you never have to copy it?”
The Reyden engine
Two years ago, Databricks took a different approach to building a new engine. Rather than studying academic papers, implementing algorithms and measuring results in isolation, the team started from actual query workloads. Databricks collected traces from trillions of real queries running on the platform. From that corpus, they trained an ML model that predicts how any algorithm will perform in practice before it’s built. The model picks the right algorithm at runtime and identifies which algorithms are worth implementing at all, not just which ones perform best in synthetic benchmarks. As Xin put it: “Knowing what to implement is one of the biggest advantages one can get”.
The engine that came out of this process is Reyden (a nod to Reynold Xin, as Ghodsi noted on stage).

Reynold Xin announcing Databricks new query engine called Reyden
Reyden handles what existing serving stacks can’t: complex joins, long-running queries and data in open formats without copying it into proprietary structures. It uses a fully asynchronous execution model to maintain consistent latency as concurrency climbs into the tens of thousands.
The first product powered by Reyden is Lakehouse//RT (RT = real time).

Reynold Xin announcing Lakehouse\\RT at Databricks Data + AI Summit 2026
Lakehouse//RT is a new SQL warehouse type in Databricks, starting with read-only analytical workloads. It delivers:
- Response times as low as 10 ms on smaller datasets
- Sub-100 ms latency on larger datasets
- 12,000 queries per second sustained throughput
- Up to 16x better performance than existing dedicated real-time serving stacks in preview customer testing
All of this runs directly against your existing Delta or Iceberg tables through Unity Catalog. No data copies. No format changes. No separate serving layer. Up to 16x better performance compared to dedicated real-time serving architectures.
Xin’s practical advice: “Challenge your conventional wisdom. If you have a separate serving stack, test it out and you might be able to collapse the two platforms into one”.
Lakehouse//RT entered beta on June 16.
Lakebase updates
Nikita Shamgunov, VP of engineering at Databricks and co-founder of Neon (the serverless Postgres company Databricks acquired in 2025), came on stage next.

Nikita Shamgunov keynote at Databricks Data + AI Summit 2026 – Databricks Summit 2026
He started by stating that agents now generate more code than humans do, so a database needs to be familiar (open source, well documented, extensible), nimble (serverless, branchable, cost effective) and mission critical (scalable, fast, reliable).
Databricks built Lakebase on Postgres, which Shamgunov called “the most advanced open source database in the world”. The main problem is that Postgres is a monolith with compute and storage tightly coupled. To fix that, Databricks decoupled the two and moved storage onto lake storage. They added “safekeepers”, based on the Paxos distributed consensus algorithm for low-latency writes, and “page servers” for low-latency reads, to compensate for object storage’s inherent latency and lack of transactional consistency. The result is fully managed, serverless Postgres running on the lake.
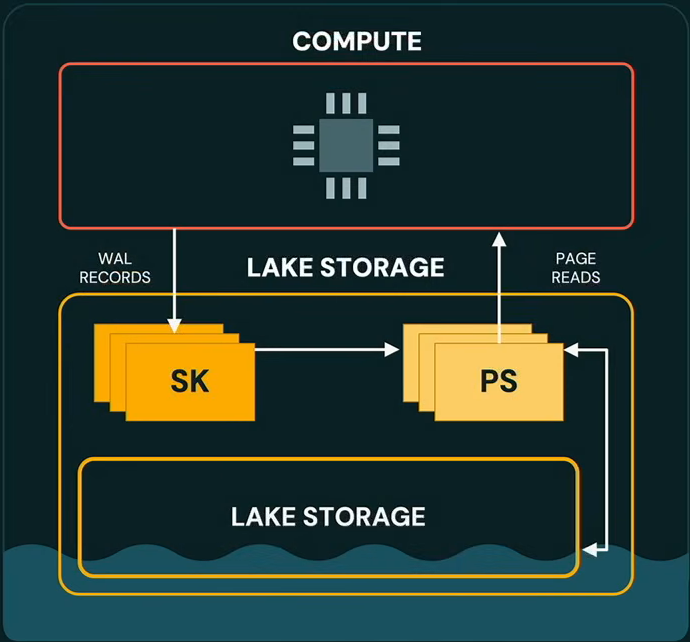
Serverless Postgres running on the lake, as presented by Nikita Shamgunov at Databricks Data + AI Summit 2026 (Source:Databricks Data + AI Summit 2026)
What Lakebase delivers today:
- New Postgres instances in under 500 milliseconds
- Scale to zero for idle dev, test and staging environments
- Any database branches in approximately 500 milliseconds
- One-click or API snapshot for safe agent experimentation with instant rollback
- Autoscaling compute with configurable minimum and maximum bounds
- 12 million database launches per day in production
New: cross-cloud disaster recovery
Shamgunov’s headline new announcement. Lakebase now supports provisioning a primary instance and a replica on a different cloud provider. In the event of a major cloud outage, you fail over instantly and continue operations without interruption. Databricks claims this is the first fully managed, cross-cloud disaster recovery for a serverless Postgres database.
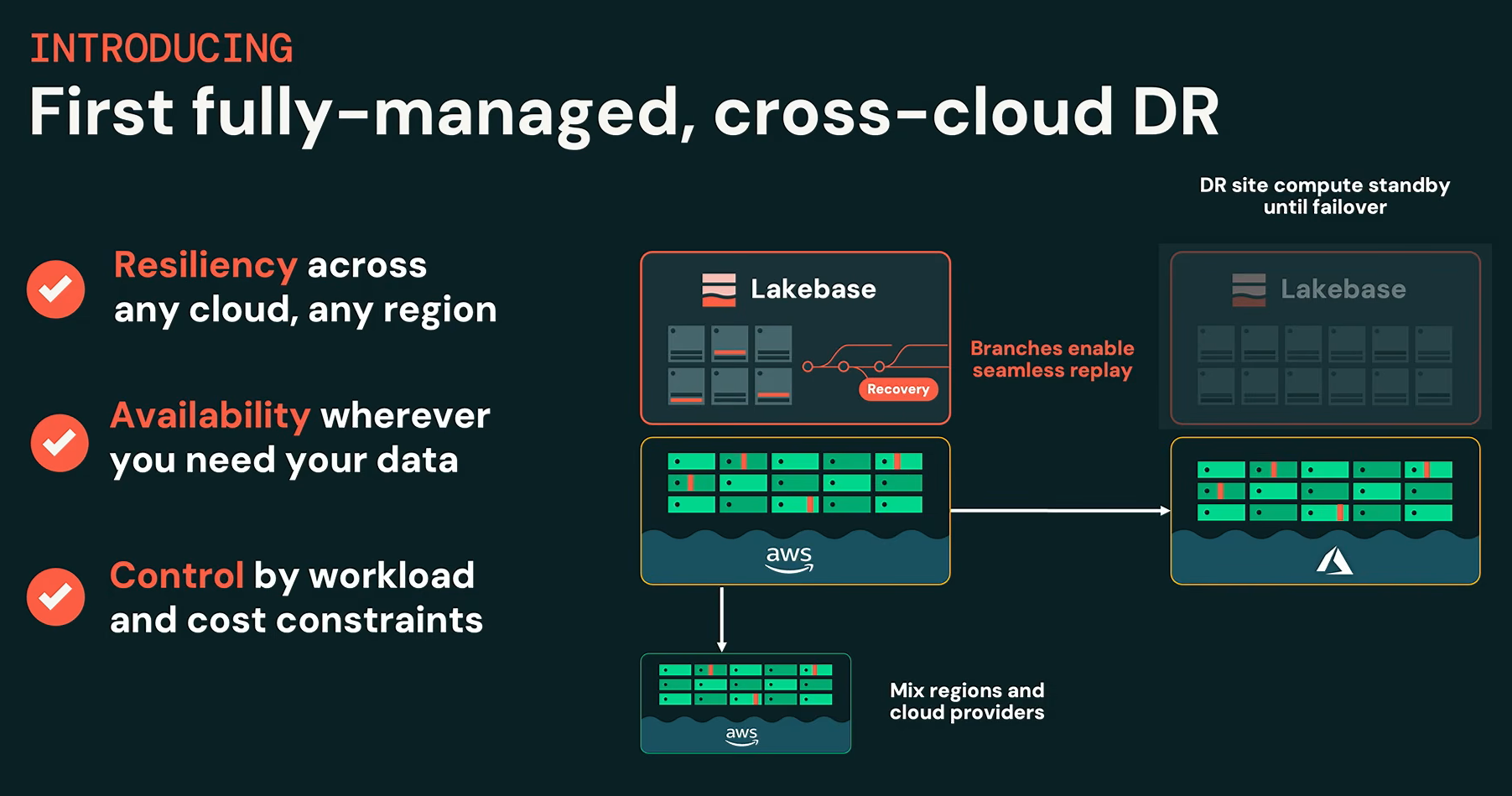
Lakebase cross-cloud disaster recovery overview, as presented by Nikita Shamgunov at Databricks Data + AI Summit 2026 (Source: Databricks Data + AI Summit 2026)
New: Lakebase Search (Beta)
Shamgunov also announced Lakebase Search, a hybrid vector and full-text retrieval engine built natively into Postgres. It uses 32x compression to enable over one billion vector indexes at low cost, making enterprise-scale semantic search practical without a separate vector database.
Mastercard shares how it’s building AI-powered business services on Lakebase
Shamgunov then brought Federico Cohen Freue, executive vice president of AI and data operations at Mastercard, on stage.

Fed Cohen keynote at Databricks Data + AI Summit 2026 – Databricks Summit 2026
Cohen Freue opened by laying out Mastercard’s scale: the company operates in 200+ countries, serves billions of cardholders and processes 150+ billion transactions a year. Mastercard’s goal is to have data and services drive over half of its revenue, which meant consolidating roughly 80 separate services onto a single platform.
“Lakebase helped us accelerate that by creating a shared foundation… [for] agents that can reason in real time and work together with that shared context”, Cohen Freue said.
One example is Mastercard’s recently announced Virtual C-Suite initiative, which uses specialized AI agents to help small businesses make executive-level decisions.
The first implementation is a virtual chief financial officer agent that helps business owners evaluate cash flow, payments and working capital decisions.
Cohen said Lakebase enables agents to share context and insights in real time.
“As one agent takes action or generates insights, it becomes instantly available for the next one”, he explained.
Trust, governance and scale remain the main focus
The session returned repeatedly to governance and tenant isolation.
Cohen highlighted an upcoming capability called Performance Pools, which must support thousands of issuing banks operating on a shared platform. While insights can be aggregated, customer data must remain isolated to satisfy regulatory, residency and privacy requirements.
Lakebase provides the underlying architecture that allows Mastercard to maintain tenant isolation while scaling services across thousands of institutions.
The company also revealed that it built a scale-ready minimum viable product in only seven weeks.
Cohen attributed much of that speed to the fact that governance, guardrails and data controls were built directly into the platform from the beginning.
“We accelerate by building the foundation from the start”, he said.
Greg Brockman and Patrick Wendell on the OpenAI-Databricks partnership
The Day 1 keynote also included a fireside conversation between Greg Brockman, co-founder, president and chairman of OpenAI and Patrick Wendell, co-founder and VP of engineering for AI at Databricks.

Fireside conversation between Greg Brockman, Co-founder and President of OpenAI and Patrick Wendell at Databricks Data + AI Summit 2026
The discussion focused on how AI models are evolving from chat assistants into systems that can perform work inside enterprise workflows.
Brockman said OpenAI’s biggest challenge is no longer building better models. It’s helping organizations connect those models to real-world applications and agent workflows.
”Connecting those models to the world is actually becoming this most important critical challenge”, he said.
He explained that OpenAI’s accelerating release cadence is the result of years of investment across research, infrastructure, inference and deployment systems.
A major theme throughout the conversation was the rise of AI agents. According to Brockman, the industry is moving beyond chat experiences toward systems that can complete tasks, use tools and participate directly in business processes.
The discussion also highlighted the importance of data. Brockman described clean, high-quality data as one of the foundational ingredients behind modern AI systems, both for model development and for understanding how customers use AI products in practice.
He and Wendell also discussed the growing partnership between Databricks and OpenAI, including integrations around Codex and Databricks AI Gateway. Brockman encouraged developers to experiment with Codex, while Wendell noted that Databricks engineers have already seen significant productivity gains from the platform.
On artificial general intelligence, Brockman pushed back gently on the idea of AGI as a single milestone: “AGI is almost a spectrum, not a moment”. He emphasized that AI progress continues while humans remain responsible for setting goals and directing outcomes.
Ghodsi then again returned briefly to connect the dots
After the Greg Brockman session, Ghodsi returned to connect the day’s database announcements.
He recapped how Databricks had already addressed analytics with Lakehouse\\RT and Reyden, while Lakebase brought PostgreSQL workloads onto the lakehouse with serverless scaling and cross-cloud disaster recovery.
According to Ghodsi, one challenge still remains: transactional and analytical systems continue to operate in separate environments, forcing organizations to move data between them.
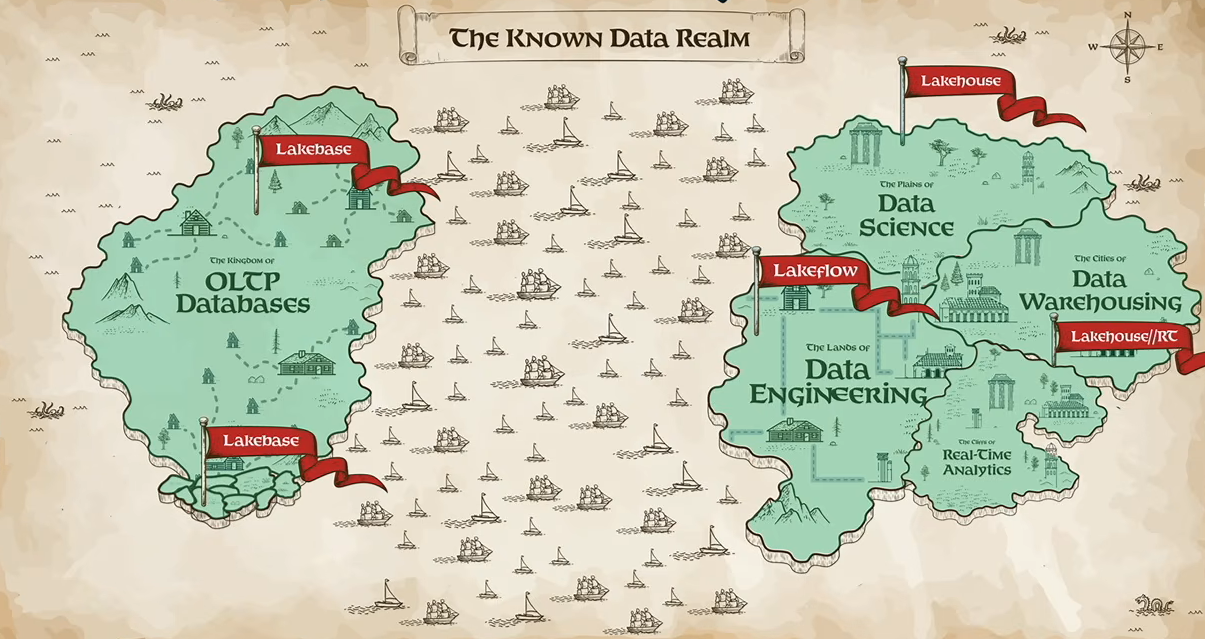
The known data realm overview, as presented by Ali Ghodsi at Databricks Data + AI Summit 2026 (Source: Databricks Data + AI Summit 2026)
That setup creates friction for data teams, especially as AI agents increasingly need access to operational and analytical data at the same time.
Reynold Xin introduces LTAP
Reynold Xin returned to address what he described as one of the biggest unsolved problems in database engineering: eliminating the divide between operational databases and analytics platforms.
He argued that most organizations still rely on change data capture (CDC) pipelines to move data from online transaction processing (OLTP) systems into analytical environments. While common, Xin noted that these pipelines are difficult to maintain and often become a source of operational issues.
“CDC doesn’t stand for change data capture. It really stands for continuous data corruption”, he said.

Xin’s case against CDC, as presented by Reynold Xin at Databricks Data + AI Summit 2026 (Source:Databricks Data + AI Summit 2026)
Xin laid out why the standard industry solution, hybrid transactional analytical processing (HTAP), has mostly failed. HTAP tries to run both workload types on a single query engine, which consistently forces a tradeoff: either OLTP performance suffers or analytical performance suffers, or the system ends up tied to proprietary formats that limit ecosystem openness.

Reynold Xin discussing about hybrid transactional analytical processing (HTAP) at Databricks Data + AI Summit 2026
To address that challenge, Xin announced LTAP (Lake Transactional Analytical Processing).

Reynold Xin announcing LTAP (Lake Transactional Analytical Processing) at Databricks Data + AI Summit 2026
Instead of forcing OLTP and analytics into the same query engine, LTAP unifies them at the storage layer.
The approach automatically converts PostgreSQL row-based data into columnar Delta Lake and Apache Iceberg formats as data is written into Lakebase. Analytical engines can then query that same data directly without CDC pipelines, ETL jobs or data copies.
“LTAP is HTAP done right”, Xin said.
Xin said the architecture allows organizations to maintain a single copy of data while preserving the performance characteristics required by both transactional and analytical workloads.
Xin also announced that Databricks plans to open source a LTAP Writer Library that converts PostgreSQL data directly into Parquet-based columnar formats, making the LTAP storage layer accessible to the broader ecosystem.

LTAP Writer Library announcement, as presented by Reynold Xin at Databricks Data + AI Summit 2026 (Source:Databricks Data + AI Summit 2026)
Holly Smith demos Lakebase and LTAP
Holly Smith, developer relations at Databricks, closed the Day 1 keynote with a live demo showing LTAP in action.

Holly Smith demonstrating Lakebase and LTAP live at Databricks Data + AI Summit 2026
Using a banking scenario, Smith showed analytical queries running in milliseconds against Lakebase transactional data with real-time data freshness and no impact on transactional performance. No CDC pipelines. No separate analytical store. One governed copy of data serving both workloads simultaneously.
Products and features announced on Day 1 of Databricks Data + AI Summit
| Product / feature | Summary |
| Genie One (GA) | Agentic AI coworker for business teams; connects to 50+ enterprise apps and the full lakehouse, grounded in Genie Ontology |
| Genie Ontology (Preview) | Live enterprise context layer with OntoRank algorithm and 50+ connected apps |
| Genie Agents (GA) | Reusable agents built from Genie One conversations, deployable to Teams and Slack |
| Genie Code (GA) | AI coding agent for data engineering and ML, grounded in Databricks platform context |
| Genie ZeroOps (Preview) | Background agent for autonomous pipeline and model operations |
| Genie App Builder (Private Preview) | Natural-language application builder for governed enterprise apps |
| Unity AI Gateway (GA) | Runtime governance for AI: spend caps, smart routing, contextual policies, MCP registry |
| Unity Catalog: Business Glossary, Domains, Metrics | Three new semantic capabilities feeding Genie Ontology |
| OpenSharing (available, announced June 10) | Open standard for sharing data, models, agent skills (Linux Foundation) |
| Agent Bricks updates | Fast sandboxes, expanded memory, broader model ecosystem |
| ZeroBus Ingest (GA) | Push-based API for high-volume event data, over 10 GB/s table throughput, Kafka-compatible API in beta |
| Spark Declarative Pipelines with Real-Time Mode (GA) | As low as 5 ms latency within Spark Declarative Pipelines, no separate Flink required |
| LakeFlow Designer (GA) | No-code pipeline design generating open source Spark Declarative Pipelines |
| LakeFlow Connect: 100+ connectors (GA) | Expanded connector catalog including community-built integrations |
| LakeFlow Jobs: 50+ integrations (GA) | Python-based workflow orchestration with 50+ external system integrations |
| Iceberg v3 support (GA) | Managed Iceberg tables in Databricks Runtime; unified data layer with Delta |
| LakeBridge (Updated, GA) | Free, AI-powered data warehouse migration tool with improved SQL conversion |
| Lakebase: cross-cloud, cross-region disaster recovery (GA) | First fully managed cross-cloud DR for serverless Postgres |
| Lakebase Search (Beta) | Hybrid vector + full-text retrieval natively in Postgres, 32x compression, 1B+ vector indexes |
| Lakehouse//RT (Beta) | New real-time SQL warehouse type on Delta/Iceberg; as low as 10 ms latency, no data copies, powered by Reyden |
| Reyden engine (Beta) | ML-trained query engine for millisecond latency at scale |
| LTAP (announced, coming soon) | Lake Transactional/Analytical Processing: unifies OLTP and analytics on one data copy |
| LTAP Writer Library (Open Source, Coming Soon) | Converts PostgreSQL data to Parquet-based columnar formats at write time |
| CustomerLake (GA) | Agentic CDP with Profile Agents for identity resolution and Campaign Agents for personalization |
| Lakewatch (GA) | Agentic SIEM on the lakehouse; stores all security data in open formats |
| Panther (intent to acquire) | Detection-as-code AI SOC platform; Databricks’ third security acquisition |
Check out this video if you want to watch the full summary of the Databricks Data + AI Summit 2026 Day 1 keynote:
Databricks Data + AI summit Day 2 (June 16) — developers, agents and the enterprise ecosystem
Day 2 focused on the developer platform and the broader partner ecosystem. Matei Zaharia, Databricks co-founder and CTO, introduced Omnigent in full. Agent Bricks expanded into a comprehensive enterprise agent platform with managed memory, Databricks Sandbox and support for new models including Kimi from Moonshot AI and Grok through a partnership with SpaceX (which acquired xAI). A pre-recorded fireside chat between Ghodsi and Satya Nadella of Microsoft explored how data context reduces token spend and how the Databricks-Microsoft integration is deepening. Justin DeBrabant introduced App Spaces, Serverless Micro Apps and Genie App Builder. Mike Del Balso announced AI Runtime along with ML-specific variants of Genie Code and Genie ZeroOps. CustomerLake and Lakewatch each received their own dedicated deep-dive sessions, and the day closed with Ghodsi tying the platform story together.
Featured speakers on day 2 of Databricks Data + AI Summit 2026:
- Ali Ghodsi (co-founder & CEO, Databricks)
- Mukesh Ambani (chairman, Reliance Industries) [pre-recorded]
- Matei Zaharia (co-founder and CTO, Databricks)
- Kasey Uhlenhuth (director of product management, Databricks)
- Satya Nadella (chairman and CEO, Microsoft) [pre-recorded]
- Justin DeBrabant (director of product management, Databricks Apps, Databricks)
- Mike Del Balso (director of product management, Databricks)
- Amber Roberts (technical marketing engineer, Databricks)
- Tasso Argyros (VP of engineering, CustomerLake, Databricks)
- Andrew Krioukov (general manager, Lakewatch, Databricks)
- Reynold Xin (co-founder, Databricks)
- Jack Naglieri (founder and CEO, Panther)
Ghodsi recaps Day 1 and introduces Mukesh Ambani
Ali Ghodsi started Day 2 by going over the four key points from the previous day: context, control, cost and choice.

Ali Ghodsi recapping Day 1 of Databricks Data + AI Summit 2026
“We think that the AI is plenty smart already”, he said. “We don’t need more intelligence for AI. We need more context”.
He made the point that avoiding vendor lock-in is central to what Databricks has been doing since its founding. “Avoiding lock-in, I think, is one of the most important things that Databricks can help with. That’s a mission we’ve been on since we started the company”.
On cost, Ghodsi was clear. “I think in the next six to 12 months, most organizations are going to see that the costs are going up so much that it’s actually prohibitive to their companies”.
Before handing the stage to Matei Zaharia, Ghodsi played a pre-recorded message from Mukesh Ambani, chairman of Reliance Industries.

Mukesh Ambani describing Reliance’s partnership with Databricks – Databricks Data + AI Summit 2026
Ambani described Reliance’s partnership with Databricks as one built on shared vision first, technology second. Reliance has migrated petabytes of data across geo, retail, energy, materials and media to serve more than 800 million customer relationships and is now scaling Databricks Genie to thousands of decision-makers across the company. His point: “If an AI solution works for India, it can serve the world”.
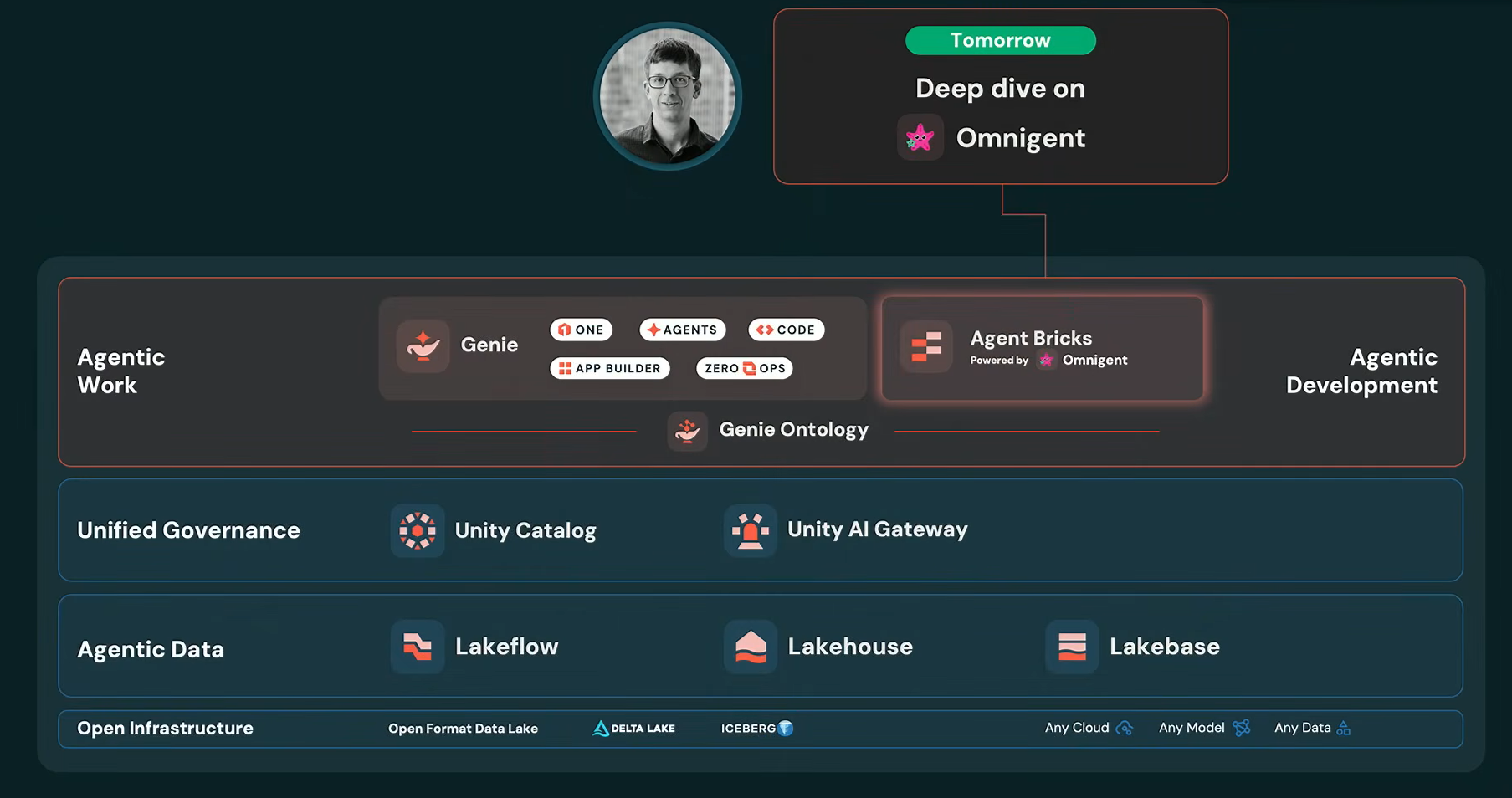
Matei Zaharia introduces Omnigent
Matei Zaharia, co-founder and CTO of Databricks, used his keynote to introduce Omnigent in full.

Matei Zaharia announcing Omnigent at Databricks Data + AI Summit 2026
Zaharia argued that while agents are becoming increasingly capable, the ecosystem around them is fragmented. Every agent framework ships with its own “harness”, the software layer that connects a model to tools, files, permissions and user interfaces. As organizations adopt multiple agents, managing interoperability, collaboration, security and cost becomes extremely difficult.
To address that challenge, Databricks created Omnigent, which Zaharia described as a “meta harness” that sits above existing agent frameworks.
Instead of replacing tools such as Claude Code, Codex or custom agent frameworks, Omnigent provides a common layer that allows organizations to compose agents, collaborate across teams and apply centralized governance controls.
According to Zaharia, the Omnigent focuses on three key areas:
1) Agent composition across different models and harnesses
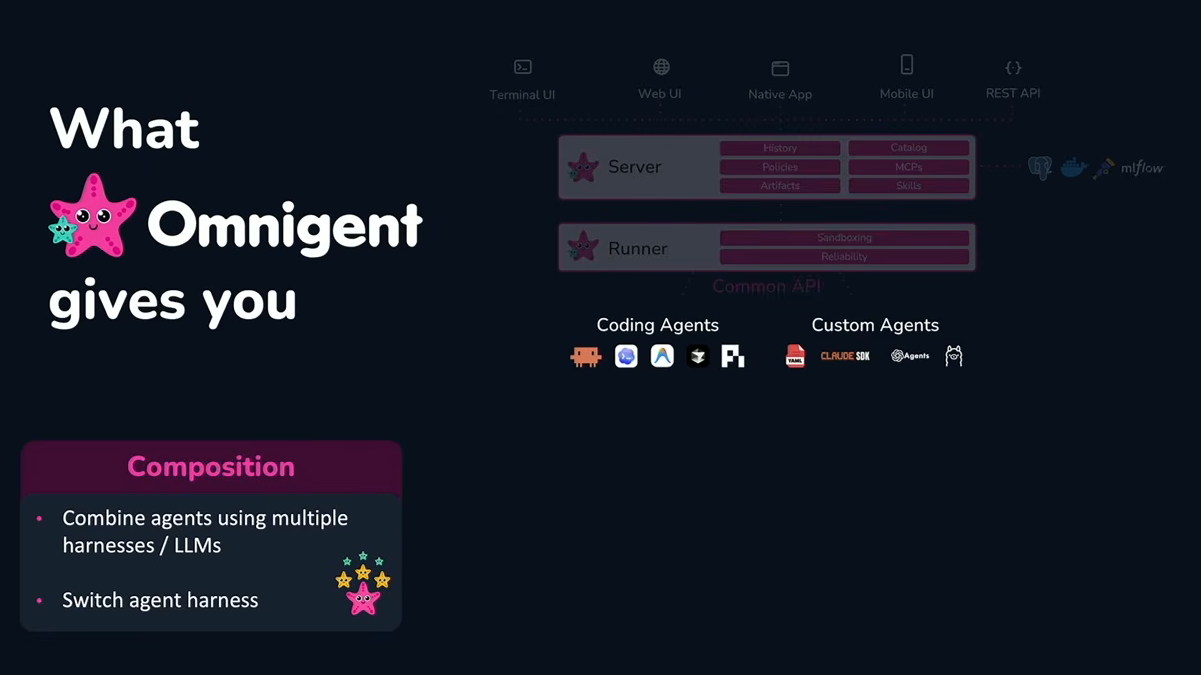
Agent composition in Omnigent, as presented by Matei Zaharia at Databricks Data + AI Summit 2026 (Source:Databricks Data + AI Summit 2026)
2) Collaboration between humans and agents
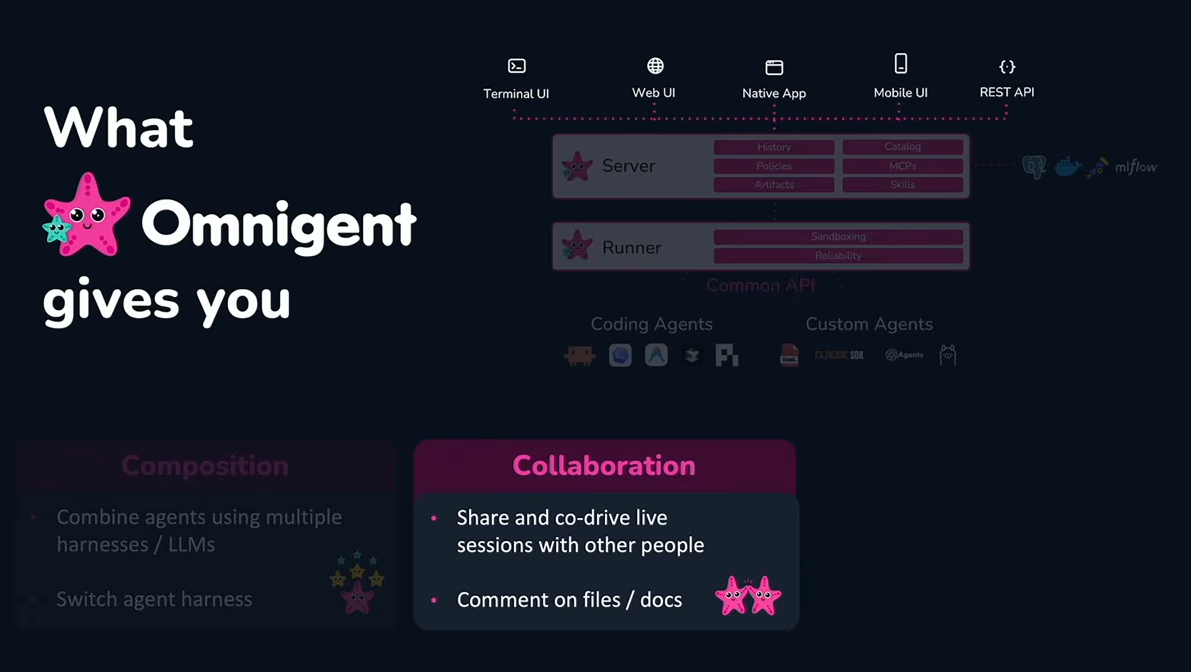
Human-agent collaboration in Omnigent, as presented by Matei Zaharia at Databricks Data + AI Summit 2026 (Source:Databricks Data + AI Summit 2026)
3) Centralized security, policy and cost controls
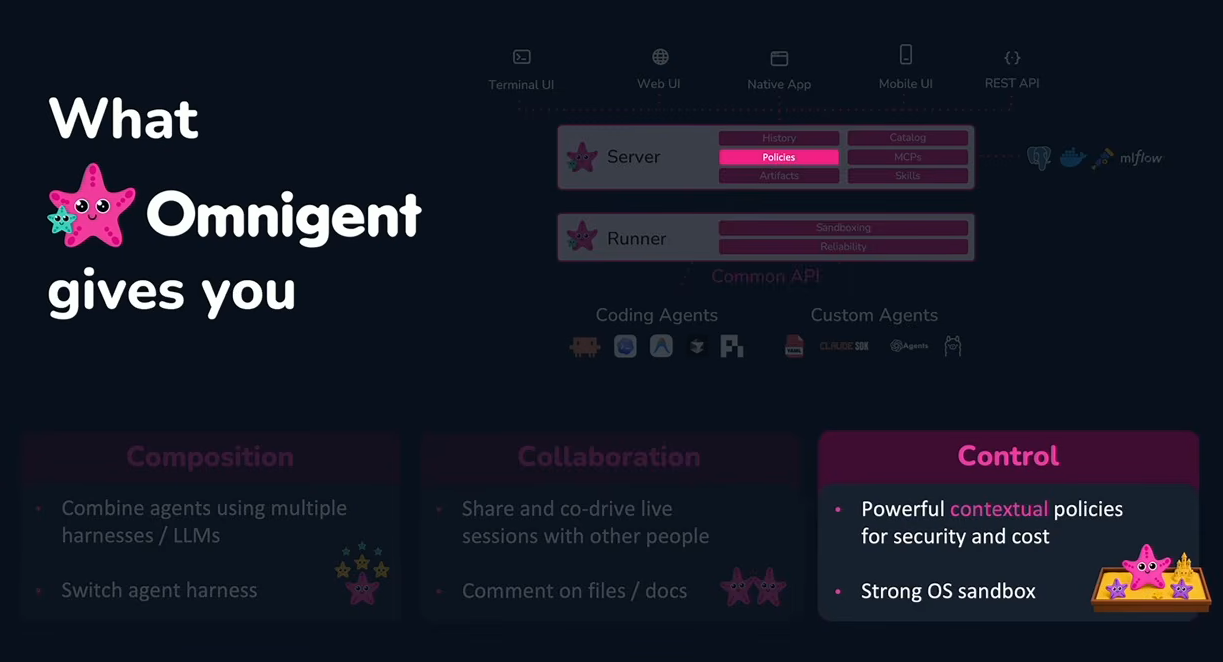
Centralized governance in Omnigent, as presented by Matei Zaharia at Databricks Data + AI Summit 2026 (Source:Databricks Data + AI Summit 2026)
One of the more notable capabilities Zaharia highlighted was contextual security policies. Instead of static allow-or-deny permissions, Omnigent can adjust what an agent is permitted to do based on actions it has already taken in the current session.
Omnigent was released as open source under the Apache 2.0 license during the summit. It runs independently of Databricks. A managed version on Databricks is in beta.
“We really think that AI needs a layer above the harness”, Zaharia said. “We think this meta-harness layer is going to be needed and will benefit from being open the same way that data formats and sharing protocols benefit from being open”.
Databricks Free Edition gets a major upgrade
Between keynote segments, Databricks announced a significant expansion of its Free Edition. It now includes five products that previously required a paid subscription: Genie Code, serverless GPUs, Lakebase, Agent Bricks and LakeFlow Designer. More than 500,000 people have used Free Edition since launch, receiving over $10 million in free credits in aggregate.

Databricks Free Edition expansion (Source:Databricks Data + AI Summit 2026)
Agent Bricks gets a major expansion
Kasey Uhlenhuth, director of product management at Databricks, opened the developer-focused half of the morning with a broad expansion of the Agent Bricks platform.

Kasey Uhlenhuth announcing the expansion of the Agent Bricks platform (Source: Databricks Data + AI Summit 2026)
During her keynote, she outlined a broad expansion of the Agent Bricks platform aimed at solving what she described as the three biggest challenges facing enterprise agent developers: choice, context and control.
Uhlenhuth noted that more than 100,000 custom agents have already been built on Agent Bricks, with over a quadrillion tokens processed through AI Gateway. She argued that building the agent itself is only a small part of the challenge.

Kasey Uhlenhuth announcing Agent Bricks at Data AI Summit 2026
To address the “choice” problem, she mentioned that Databricks announced expanded model support including Kimi and Grok (through a partnership with SpaceX, which owns xAI), alongside existing support for OpenAI, Anthropic, Gemini and Qwen.

Expanded model support across Agent Bricks, as presented by Kasey Uhlenhuth at Databricks Data + AI Summit 2026 (Source:Databricks Data + AI Summit 2026)
She also highlighted support for custom reinforcement learning models, Omnigent deployment inside Databricks and continued compatibility with frameworks including OpenAI Agent SDK, CrewAI, LangGraph and others.

Agent Bricks framework compatibility overview, as presented by Kasey Uhlenhuth at Databricks Data + AI Summit 2026 (Source:Databricks Data + AI Summit 2026)
For context management – which Databricks sees as the foundation for effective agents – Uhlenhuth announced several new capabilities:
- Agent Memory Services for storing user preferences, conversation history and sessions (backed by Lakebase)
- Managed external MCP integrations for connecting agents to third-party systems
- Document Intelligence for extracting and classifying information from PDFs, invoices and contracts (GA)
- Integration with Genie Ontology for improved context discovery and retrieval

Databricks Agent Bricks new features, as presented by Kasey Uhlenhuth at Databricks Data + AI Summit 2026 (Source:Databricks Data + AI Summit 2026)
All context assets remain governed through Unity Catalog.
Databricks Sandbox and Unity AI Gateway upgrades
The biggest announcements centered on governance and operational control.
Uhlenhuth introduced Databricks Sandbox, a new secure execution environment that allows agents to run code inside isolated virtual machines with governed access to enterprise data.

Kasey Uhlenhuth announcing Databricks Sandbox at Databricks Data + AI Summit 2026
“Databricks Sandbox provides VMs that you can have your agents securely run and execute code in”.
She also unveiled major upgrades to Unity AI Gateway, which Databricks positioned as a centralized governance layer for models, agents, MCP servers and AI skills.

Kasey Uhlenhuth announcing Databricks Unity AI Gateway at Databricks Data + AI Summit 2026
New AI Gateway capabilities are:
- Agent Registry for inventorying enterprise AI assets
- Context-aware security policies
- Budget controls and hard spend limits
- Smart Routing: automatically directs simple requests to lower-cost models while reserving premium models for complex workloads
- Cross-provider failover support
- Centralized agent tracing using MLflow and Unity Catalog
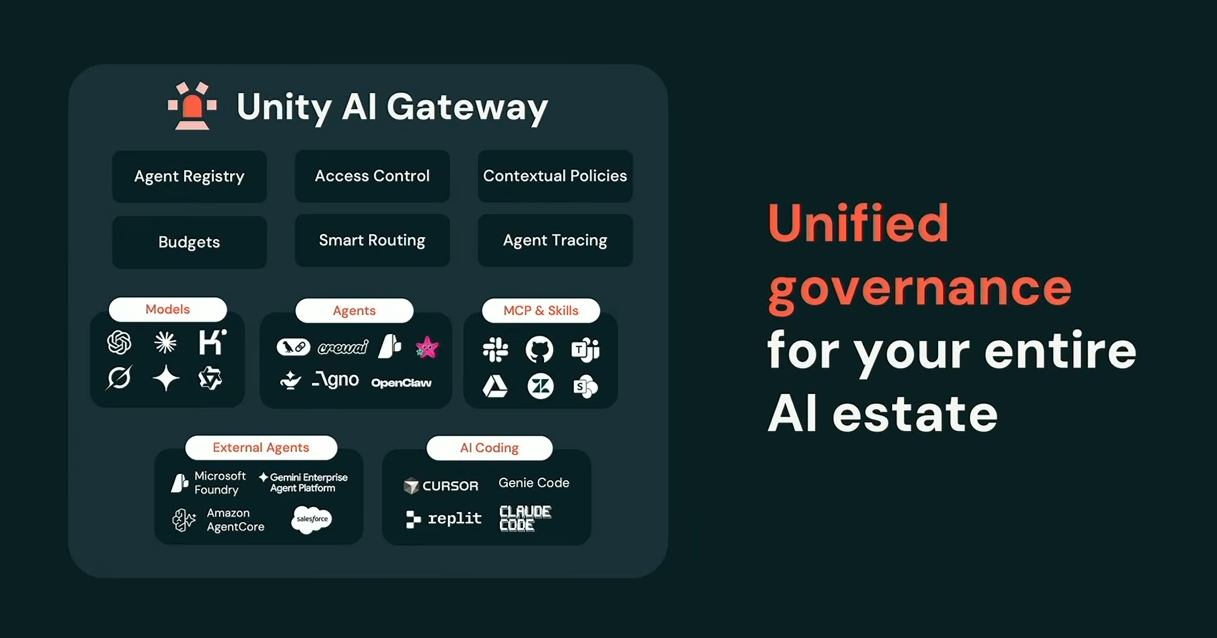
Unity AI Gateway overview, as presented by Kasey Uhlenhuth at Databricks Data + AI Summit 2026 (Source:Databricks Data + AI Summit 2026)
One of the more notable additions was Smart Routing, which automatically directs simple requests to lower-cost models while reserving premium models for more complex workloads.
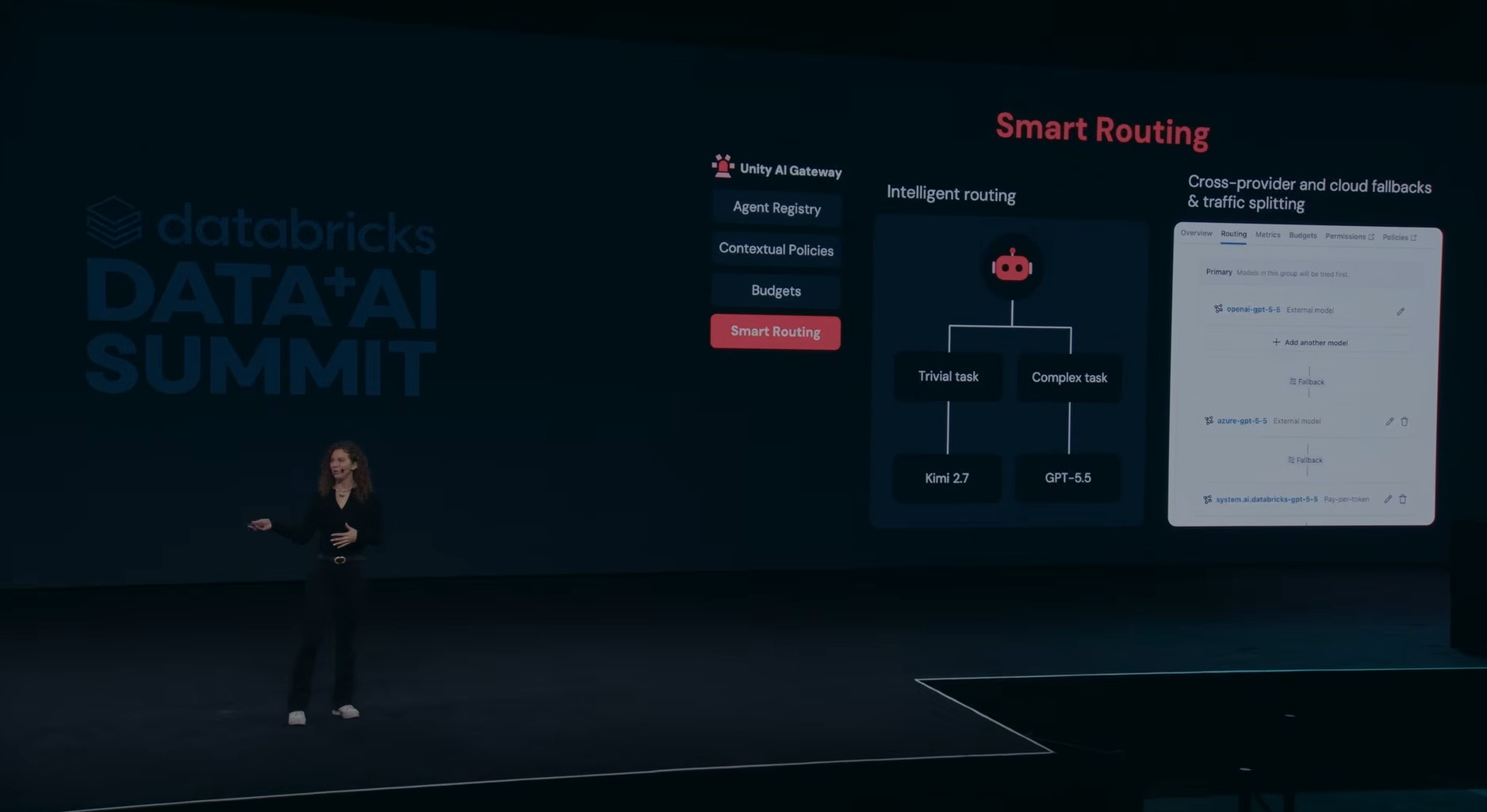
Kasey Uhlenhuth announcing Smart Routing at Databricks Data + AI Summit 2026
Ankit Mathur, a software engineer at Databricks, followed with a live demo of Unity AI Gateway.
He demoed three of the five capabilities Uhlenhuth had just described:
- Budget management
- Smart model routing
- Agent tracing

Ankit Mathur demoing at Databricks Data + AI Summit 2026 – Databricks Summit 2026
Day 2: Chat between Ali Ghodsi and Satya Nadella
The Day 2 keynote featured a pre-recorded fireside conversation between Databricks CEO Ali Ghodsi and Microsoft chairman and CEO Satya Nadella.

Pre-recorded conversation between Databricks CEO Ali Ghodsi and Microsoft Chairman and CEO Satya Nadella at Data AI Summit 2026
Nadella argued that the industry is moving beyond what he called “frontier model worship” and toward building what he described as a “frontier ecosystem”, where enterprises use their own data, context and intellectual property to create differentiated AI systems.
He emphasized that enterprise data is becoming even more valuable in the AI era because it provides the context that makes AI systems useful and efficient. Organizations that build strong context layers can reduce token consumption while producing better outputs from foundation models. He also introduced the concept of “token capital” alongside human capital, arguing that future enterprises will combine both to build institutional knowledge and competitive advantage.
The discussion also covered deepening integration between Databricks and Microsoft’s AI ecosystem. Ghodsi pointed to integrations between Databricks Genie, Microsoft 365 Copilot, Teams, Copilot Studio, Entra and OneLake, while Nadella said these integrations help customers access trusted enterprise context directly inside the tools employees already use.
Specific integrations announced at the summit include:
- Genie for Microsoft Teams and M365 Copilot (Beta): Tag Genie in a Teams thread and get Unity Catalog-governed answers from the Databricks lakehouse without leaving the conversation
- Genie in M365 Copilot Cowork (Beta): Available immediately; anchors Cowork tasks with Genie Ontology for trusted data intelligence inside workflows
- Azure Databricks Excel Add-in (Public Preview): Brings driverless analytics directly inside Excel, letting teams query Unity Catalog metric views and lakehouse data without leaving their spreadsheet
Ghodsi closed the conversation by emphasizing a shared goal: helping enterprises define and protect their unique knowledge in the AI era while building systems that turn that knowledge into lasting business value.
Databricks expands Apps with App Spaces, Serverless Micro Apps and Genie App Builder
Justin DeBrabant, director of product management for Databricks Apps, presented the next wave of application platform updates.

Justin DeBrabant keynote at Databricks Data + AI Summit 2026 – Databricks Summit 2026
Debrabant argued that coding is no longer the bottleneck. Thanks to coding agents and AI-assisted development, creating software has become much easier. The bigger challenge is connecting applications to enterprise data while maintaining governance, security and operational controls.
One key highlight of the talk, Debrabant revealed that more than 5,000 customers are now using Databricks Apps and have collectively built 150,000 applications, representing 6x growth year over year.

Justin DeBrabant revealing current stat of Databricks Apps
App Spaces brings governance to thousands of apps
One of the biggest announcements was App Spaces, a new governance construct designed to manage large numbers of enterprise applications.
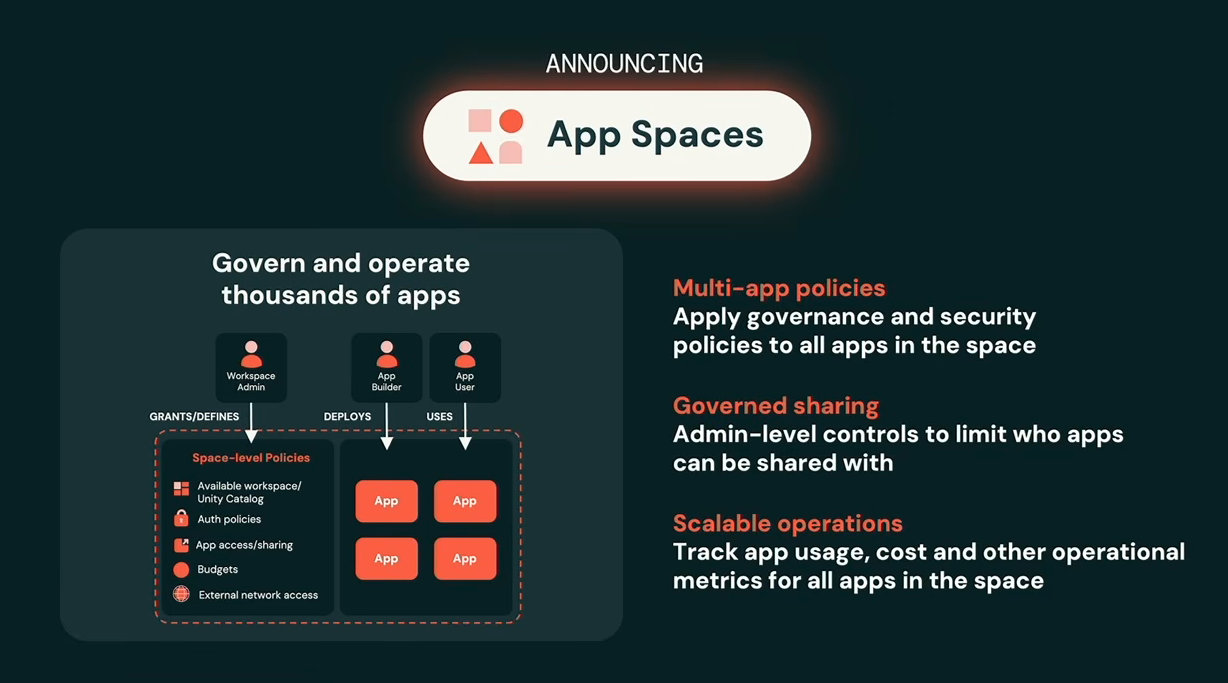
Databricks App Spaces overview, as presented by Justin DeBrabant at Databricks Data + AI Summit 2026 (Source:Databricks Data + AI Summit 2026)
According to Debrabant, organizations are dealing with thousands of internally built applications. App Spaces allows admins to apply policies, security controls, sharing rules and operational oversight across groups of apps rather than managing each application individually.
Serverless Micro Apps target lightweight workloads
Another big announcement was Serverless Micro Apps, a new architecture for lightweight applications that do not need always-on infrastructure.

Justin DeBrabant announcing Serverless Micro Apps at Databricks Data + AI Summit 2026
The new deployment model supports:
- Fractional CPU and memory allocation
- Scale-to-zero capabilities
- Fast startup times
- Kernel-level isolation through micro virtual machines (microVMs)
New Genie App Builder
The headline announcement was Genie App Builder, a new AI-powered application development experience built on Databricks Genie.
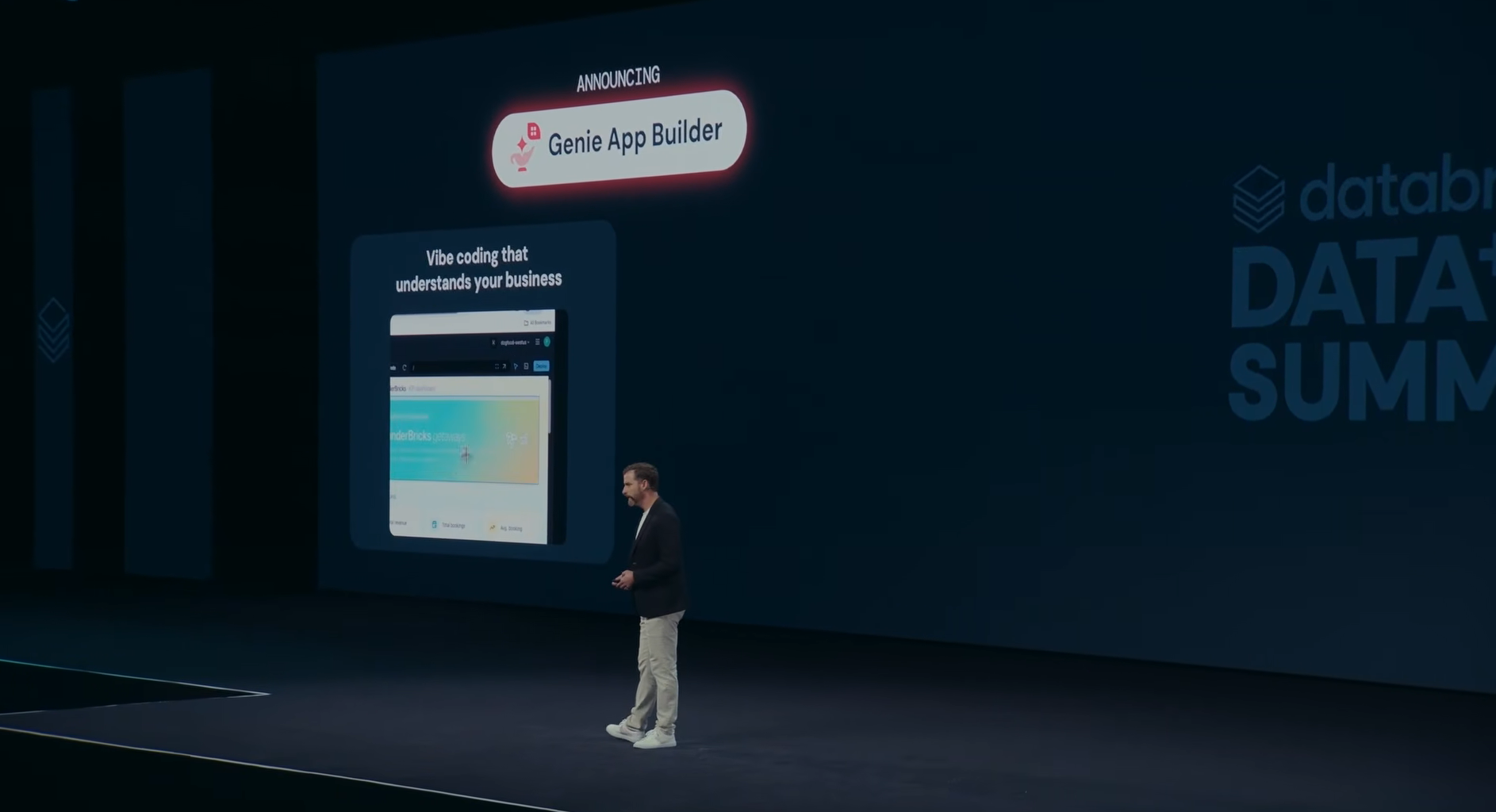
Justin DeBrabant announcing Genie App Builder at Databricks Data + AI Summit 2026
Debrabant described it as a way to turn AI-generated prototypes into production-ready applications while automatically respecting enterprise governance rules.
Using business context from Genie, App Spaces and Databricks resources, Genie App Builder can connect applications to approved data sources, validate permissions, enforce sharing policies and deploy applications directly into production environments.
During the demo, he showed how a prototype inventory management application could be imported, connected to live Databricks resources, modified through natural-language prompts and deployed in seconds, all while staying within governance boundaries.
“Genie App Builder is vibe coding that understands your business”, he said.
Genie Code for ML and Genie ZeroOps for ML
Mike Del Balso, director of product management at Databricks, opened by stating that the machine learning industry has chased one goal for years, making ML easier and more automated.

Mike Del Balso keynote at Databricks Data + AI Summit 2026 – Databricks Summit 2026
He argued that GenAI has not cut the need for ML. It has increased it. More products, more pricing decisions, more fraud checks and more loan decisions all add up to more decisions that teams want to automate. His answer was agentic automation, built on three things: serverless infrastructure, one governed data model across the ML life cycle and governance on agent actions.
To support that vision, Del Balso announced several new Databricks machine learning capabilities.
First announcement was AI Runtime, a new serverless GPU compute option for deep learning and large language model (LLM) training. The service provides on-demand GPU infrastructure without upfront commitments and now supports multi-node training for larger workloads.

Databricks AI Runtime announcement, as presented by Mike Del Balso at Databricks Data + AI Summit 2026 (Source:Databricks Data + AI Summit 2026)
Second announcement was Genie Code for Machine Learning, an enhanced version of Genie Code built specifically for machine learning workflows. It uses organizational context from Genie Ontology to understand how teams build features, train models, run evaluations and manage production pipelines, making it considerably more useful than a generic coding assistant for ML-specific tasks.
According to Del Balso, this allows Genie Code to behave more like an experienced machine learning engineer rather than a generic coding assistant.
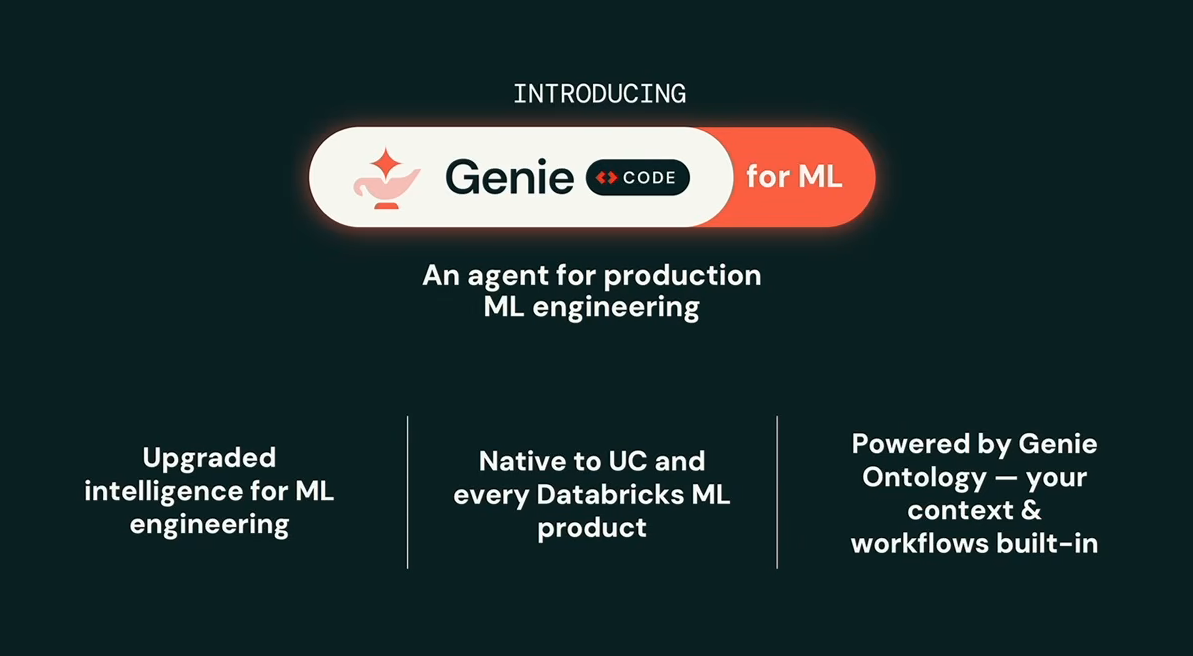
Databricks Genie Code for ML announcement, as presented by Mike Del Balso at Databricks Data + AI Summit 2026 (Source:Databricks Data + AI Summit 2026)
Finally, Genie ZeroOps for Machine Learning, an autonomous operations agent designed to monitor production ML systems. Instead of simply identifying issues, it investigates root causes, proposes fixes and presents recommendations for human approval before any change touches production.

Databricks Genie Code for ML announcement, as presented by Mike Del Balso at Databricks Data + AI Summit 2026 (Source:Databricks Data + AI Summit 2026)
Del Balso positioned ZeroOps as a major shift for machine learning operations, moving teams away from constant monitoring and toward agent-assisted management of production models.
Amber Roberts then took over for the live demo.

Amber Roberts live demo at Databricks Data + AI Summit 2026
Del Balso positioned ZeroOps for ML as a significant shift for ML operations teams, moving them away from constant manual monitoring toward agent-assisted management of production models. Amber Roberts followed with a live demo showing how AI Runtime, Genie Code for ML and Genie ZeroOps for ML work together across the ML lifecycle.
CustomerLake brings an agentic CDP to the lakehouse
Tasso Argyros, head of engineering management for CustomerLake at Databricks, introduced CustomerLake with a clear argument for why the existing CDP architecture can’t support where marketing is heading.

Tasso Argyros keynote at Databricks Data + AI Summit 2026 – Databricks Summit 2026
The problem he laid out: buyers are already consulting LLMs before purchases, and the next step is fully autonomous agents handling research, price discovery and transactions. “Buying decisions are now happening in seconds or minutes. Not days or weeks”, he said. That breaks the traditional campaign model, which runs as a waterfall, taking weeks from strategy through activation. It can’t handle real-time, agent-driven commerce.
His answer is what he calls Infinity Campaigns: evergreen campaigns with no fixed start or end date, powered by individual agents assigned to each customer. Each agent reads the latest customer signals, determines the next best action, generates personalized content and feeds the response back into a continuous loop. Marketers stay in control as strategists and approvers, but agents handle one-to-one execution at scale.
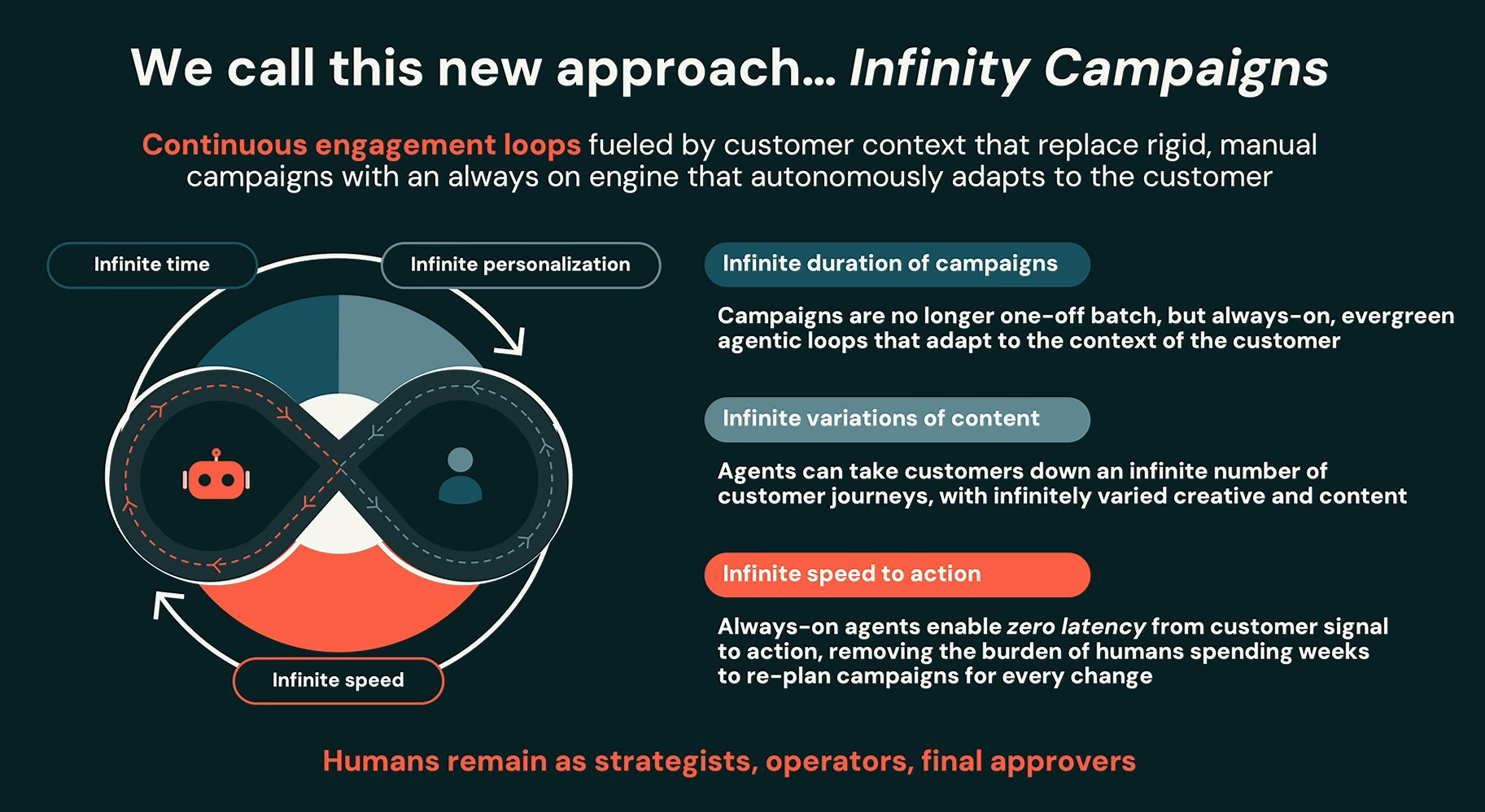
Infinity Campaigns approach, as presented by Tasso Argyros at Databricks Data + AI Summit 2026 (Source:Databricks Data + AI Summit 2026)
“In order to make agents work, you need data, but you also need context and you need data and context to be where the agents live”, Argyros said. Traditional CDPs can’t support this because they were built as middleware, detached from the data layer.
What CustomerLake is
“CustomerLake is an agentic CDP built specifically for the Databricks platform”, Argyros announced. Data stays in the lakehouse, Unity Catalog governance applies automatically and the product is built for business users, not just engineers.

Tasso Argyros announcing CustomerLake at Databricks Data + AI Summit 2026
CustomerLake ships with two AI-powered modules designed to automate the entire customer engagement lifecycle.
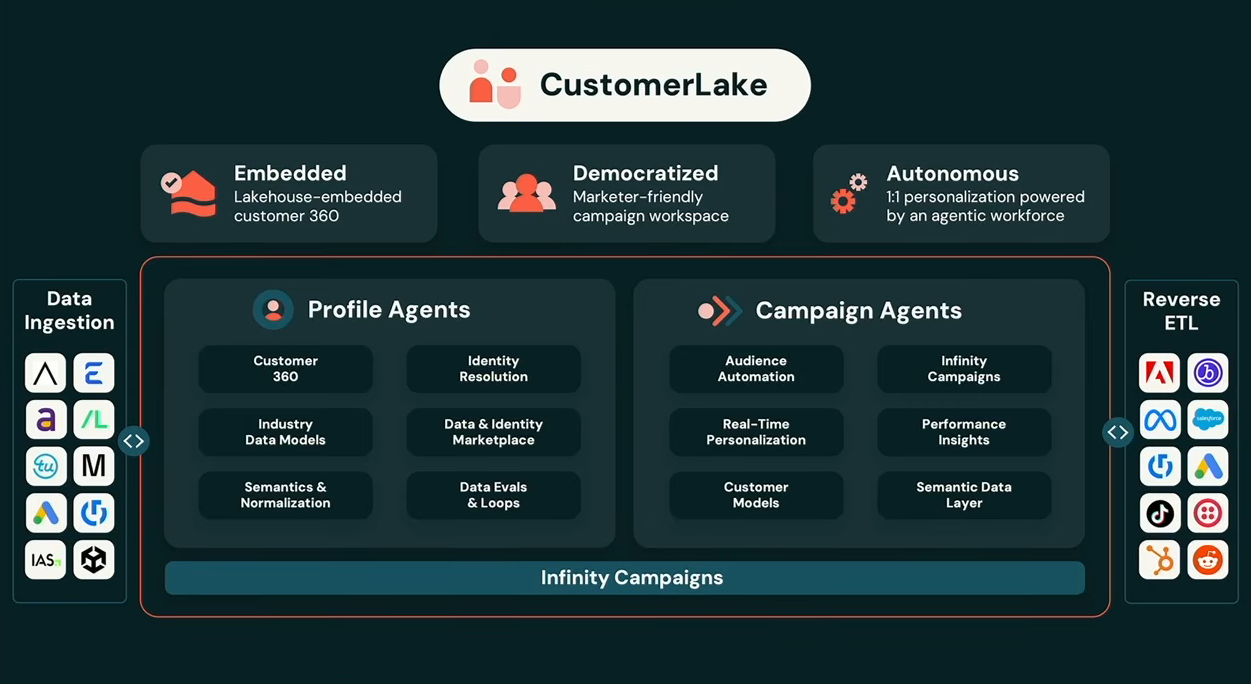
CustomerLake architecture overview, as presented by Tasso Argyros at Databricks Data + AI Summit 2026 (Source:Databricks Data + AI Summit 2026)
Profile Agents automatically build Customer 360 profiles by:
- Ingesting data through Lakeflow Connect
- Cleaning and enriching customer records
- Performing agentic identity resolution across first-party data
- Supporting privacy-preserving third-party identity resolution through Databricks Clean Rooms
- Continuously improving profile quality through an agent feedback loop
A major addition is agentic identity resolution, which combines AI-generated matching rules, large language models (LLMs) and human review to identify duplicate customer records. Databricks positioned this as an improvement over traditional SQL rule-based or machine learning identity matching.

Tasso Argyros announcing agentic identity resolution at Databricks Data + AI Summit 2026
The second module, Campaign Agents, focuses on marketing execution. Using natural language prompts, marketers can generate campaign briefs, build audiences, launch Infinity Campaigns and review AI-generated recommendations through a business-focused interface.
CustomerLake also introduces native Reverse ETL, allowing customer data stored in the Lakehouse to be delivered directly to downstream advertising, marketing and customer engagement platforms.
Argyros also announced support for around 20 managed connectors at launch, with additional integrations planned later this year.
Managed Reverse ETL connectors, as presented by Tasso Argyros at Databricks Data + AI Summit 2026 (Source: Databricks Data + AI Summit 2026)
After wrapping, Argyros handed off to Andrew, general manager of Lakewatch, for the next segment.
Lakewatch takes security operations into the AI era
Andrew Krioukov, general manager of Lakewatch at Databricks, took the stage to give the platform its first deep-dive session at the summit. Lakewatch was first announced in April 2026 when Databricks entered the cybersecurity market at RSA Conference 2026. The Day 2 session added more technical context and confirmed that Databricks acquired Panther specifically to strengthen the Lakewatch roadmap.

Andrew Krioukov keynote at Databricks Data + AI Summit 2026 – Databricks Summit 2026
Krioukov opened with one straight fact that large language models (LLMs) can now find previously unknown software vulnerabilities in any codebase, open source or closed. What used to require nation-state-level teams of reverse engineers working for months is now accessible to anyone with the right LLM.
He cited a documented case. Anthropic reported that hackers used Claude to attack the Mexican government. “You can actually read the entire chat log”, Krioukov said. The attackers directed the agent to scan for vulnerabilities across a set of servers. It found some. They asked it to attack one. It broke in. They escalated to root access by having the agent find a vulnerability in a crontab entry. The attackers left with 200 million personnel records and gigabytes of sensitive data. The entire operation ran through an agent.
“Now just about anyone with access to an LLM can put on an attack at a scale and speed that was previously unimaginable”, Krioukov said.
Most enterprise security operations teams rely on a security information and event management (SIEM) tool. The standard workflow has three steps: ingest telemetry from laptops, servers and identity systems; write detection rules to flag suspicious behavior; and route alerts to an incident response team that investigates and acts.
The problem is that SIEMs weren’t built for the current scale. Krioukov outlined three specific failures:
The first is data completeness. Pricing and scale constraints force teams into workarounds: discarding data older than 30 days, running filtering tools to reduce incoming volume and skipping entire data categories SIEMs can’t handle at all. That last bucket includes LLM logs, code repositories, Jira and Slack messages, which is extremely valuable.
The second problem is alert volume. A typical large organization dealt with over 7,000 alerts per week in 2020; that number is now over 30,000 per week, with each alert taking roughly 30 minutes to investigate manually. Krioukov stated, at that rate, you’d need a team of over 400 people just to keep pace with today’s alert volume, before accounting for the acceleration that agentic attacks will bring.
The third problem is proprietary data silos. Data locked across separate systems can’t be analyzed holistically, leaving gaps in detection coverage.
“The reality is that with the tools we have today, we don’t stand a chance in meeting these agentic threats”, he said.
What is Lakewatch?
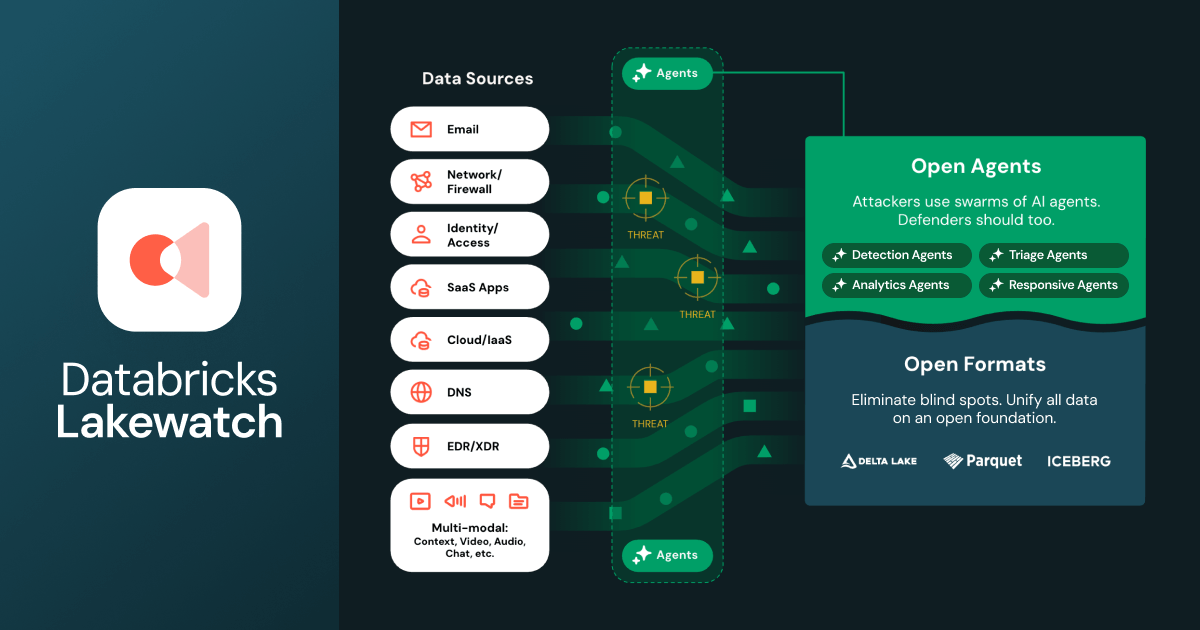
Databricks Lakewatch, as presented by Andrew Krioukov at Databricks Data + AI Summit 2026 (Source: Databricks Data + AI Summit 2026)
Lakewatch is Databricks’ agentic security lakehouse, built on the Databricks platform. All data is stored in open formats. Unity Catalog handles governance and compliance. Agent Bricks and Genie layer on top to automate manual workflows.
The core pitch is simple: make it cheap and easy to bring in any data type, structured, unstructured or semi-structured, then apply agents at every stage of the security operations workflow.
Agents operate across all three stages of the security workflow:
- On the ingest path, agents handle extract, transform and load (ETL) and data normalization automatically; if a source schema changes, agents correct the pipeline without interrupting data flow
- On the detection path, agents help author queries and detection rules
- On the investigation path, agents automatically investigate incidents so analysts receive a complete case summary rather than a raw alert, letting them verify the work and approve the recommended action
Krioukov also flagged the Panther Labs acquisition, which Databricks CEO Ali had announced the previous day. Panther’s CEO Jack and Databricks co-founder Reynold were scheduled to discuss it in the session immediately following.
Krioukov handed off to Michael Anderson, Lakewatch’s tech lead, who followed with a live product demo.
Reynold Xin and Jack on the Panther acquisition
Databricks shared more detail on the Panther acquisition through a fireside conversation between Reynold Xin and Panther founder and CEO Jack Naglieri. The discussion focused on why the two companies are joining forces and how AI agents are changing security operations.

Fireside chat between Databricks co-founder Reynold Xin and Panther founder Jack at Databricks Data + AI Summit 2026
Jack explained that Panther was created after his team at Airbnb found traditional SIEM platforms too slow, expensive and difficult to operate at scale. As LLMs matured, Panther rebuilt its platform around AI agents that automatically generate detections, triage alerts and investigate incidents.
“The SOC is at an inflection point: AI is changing how attacks are launched and defenders can now finally keep pace with them”, he said.
Looking ahead, Jack described the combination of Panther’s AI-driven security operations with the Databricks Data Intelligence Platform as giving security agents access to richer enterprise context, improving threat detection, incident investigation and compliance workflows while keeping security teams focused on security rather than data infrastructure.
Panther is Databricks’ third security acquisition, following Antimatter and SiftD.ai.
For more detail: Databricks Agrees to Acquire Panther, Further Establishing the Security Lakehouse Category – Databricks
Xin wrapped the session and passed back to Ali Ghodsi for closing remarks.
Ali Ghodsi closes Day 2 with Databricks’ AI vision
Ghodsi closed Day 3 by tying together the announcements from both keynote days around a single theme: giving AI the enterprise context it needs to do useful work.
He recapped the major launches across the platform, including Lakeflow for data ingestion, Lakehouse\\RT for low-latency analytics, Lakebase with Lakebridge for operational applications, Genie Ontology for enterprise context, GenieOne as the unified AI interface, Genie Agents, Genie Code, ZeroOps, Databricks Apps, Agent Bricks, Lakewatch and Customer Lake.

Ali Ghodsi recapping major launches of Day 1 and Day 2 of Databricks Data + AI Summit 2026
According to Ghodsi, these products support four pillars of the Databricks AI strategy: open choice across data, models and cloud providers, unified governance, centralized cost controls and enterprise context powered by Genie Ontology. Together, they aim to help organizations build AI applications without vendor lock-in while keeping data, governance and operational controls in one platform.
“We want you to have any data, any model and any harness, no cloud lock-in for your whole infrastructure” — Ali Ghodsi, Co-founder and CEO, Databricks
Products and features announced on Day 2 of Databricks Data + AI summit
| Product / feature | Description |
| Omnigent (open source) | Meta harness for composing, governing and collaborating across agent frameworks; Apache 2.0 license; managed version in Beta |
| Databricks Free Edition expansion (GA) | Five new products at no cost: Genie Code, serverless GPUs, Lakebase, Agent Bricks, LakeFlow Designer; 500,000+ users |
| Agent Bricks: Kimi (Moonshot AI) support | Expanded model support adding Kimi from Moonshot AI |
| Agent Bricks: Grok (SpaceX/xAI) model support | Partnership with SpaceX to make Grok models natively available on Agent Bricks |
| Agent Bricks: Agent Memory Services | Store user preferences, conversation history and sessions across agent interactions, backed by Lakebase |
| Agent Bricks: Document Intelligence (GA) | Extract and classify information from PDFs, invoices and contracts |
| Databricks Sandbox | Secure agent code execution in isolated microVMs with governed data access |
| Unity AI Gateway: Smart Routing | Auto-route requests to the right model tier based on complexity and cost |
| Unity AI Gateway: Agent Registry | Centralized inventory of all enterprise AI assets |
| Unity AI Gateway: Cross-provider failover | Automatic failover between model providers |
| Genie for Microsoft Teams / M365 Copilot (Beta) | Tag Genie in Teams threads for governed lakehouse answers without leaving the conversation |
| Genie in M365 Copilot Cowork (Beta) | Anchors Cowork tasks with Genie Ontology for trusted data intelligence inside M365 workflows |
| Azure Databricks Excel Add-in (Public Preview) | Bring Unity Catalog metric views and lakehouse data into Excel with write-back support |
| AI Runtime (Public Preview) | Serverless GPU training with multi-node support; no upfront commitments or cluster management |
| Genie Code for ML (Public Preview) | Genie Ontology-aware coding agent for ML workflows |
| Genie ZeroOps for ML (Public Preview) | Autonomous production ML monitoring, root cause analysis and human-approved fix workflow |
| CustomerLake: Infinity Campaigns | Per-customer agent campaigns with no fixed start or end date |
| CustomerLake: Agentic identity resolution | LLM-powered customer deduplication replacing SQL rule-based matching |
| CustomerLake: Reverse ETL (GA) | Deliver lakehouse customer data directly to 20+ advertising and engagement platforms |
| App Spaces (GA) | Group-level governance, policies and oversight for enterprise application portfolios |
| Serverless Micro Apps (GA) | Fractional compute, scale-to-zero, microVM isolation for lightweight apps |
| Genie App Builder (Private Preview) | Governed vibe coding that understands enterprise context and deploys with existing permissions |
| Panther acquisition (intent to acquire) | 100+ security integrations, detection-as-code, AI SOC workflows; founded by Jack Naglieri; Databricks’ third security acquisition |
Check out this video if you want to watch the full summary of the Databricks Data + AI Summit 2026 Day 2 keynote:
Hands-on sessions and wrap-up (June 17-18)
After two days of major announcements, the summit shifted its weight toward implementation. Days 3 and 4 (June 17-18) ran 800+ breakout sessions covering data engineering, analytics, governance, application development, cybersecurity, ML and AI agents. Most of the technical sessions were designed to go deeper on products announced during the keynotes, giving practitioners a place to ask hard questions and get hands-on exposure.
Instructor-led workshops and technical labs covered:
- Agent Bricks and agent development
- Omnigent architecture and deployment
- Genie Code and Genie Agents
- Unity AI Gateway configuration and governance
- Genie Ontology setup
- LakeFlow ingestion, transformation and orchestration
- Lakehouse//RT deployment and benchmarking
- Lakebase provisioning, branching and disaster recovery
- Databricks Apps and Genie App Builder
- Unity Catalog governance
- ML engineering and model evaluation
- Data engineering and streaming with Spark Declarative Pipelines
- Open table formats: Delta Lake and Apache Iceberg
Sessions also covered performance tuning, migration strategies from legacy data warehouses using LakeBridge, real-time analytics patterns, enterprise AI governance and running AI agents in production.
Partners session
The partner ecosystem was a significant presence throughout the summit. Technology vendors, cloud providers, system integrators and software companies demonstrated how they’re extending Databricks across AI development, governance, cybersecurity, application development and enterprise data platforms.
Companies with a significant presence included Microsoft, NVIDIA, OpenAI, Anthropic, LangChain, LlamaIndex, Replit, Atlan, Infosys, Accenture, Deloitte, Salesforce and more than 240 other sponsors and partners.
Many discussions addressed a common challenge: moving AI from prototypes into governed production environments. Topics included enterprise governance, semantic context, infrastructure modernization, AI operations, cybersecurity, customer data platforms and industry-specific deployment patterns.
Customer stories
Customer presentations became one of the strongest parts of the latter half of the summit. Engineering teams described how they’re running the Databricks Data Intelligence Platform in production, including the architectural decisions they made, the problems they encountered and the tradeoffs they accepted.
Featured organizations included:
- PepsiCo
- Mastercard
- AstraZeneca
- Atlassian
- 7-Eleven
- Virgin Atlantic
- Nationwide
- Circle K
- Adidas
- Novo Nordisk
- Fox Corporation
- Lululemon
- Mercedes-Benz
- Nasdaq
- HP
- Workday
Their sessions covered governance, enterprise AI, customer data platforms, streaming pipelines, data engineering, ML, application development, security and large-scale analytics.
Training and certification
Instructor-led training and certification programs ran throughout the conference. Databricks offered more than 25 lab-based training courses covering Lakebase, Genie, AI application development, vibe coding, data engineering and core platform capabilities. Lab-based formats gave attendees direct hands-on time with new technologies under expert guidance.
Networking sessions
Across all four days, attendees met Databricks engineers, product teams, customers and partners in the Expo Hall and at dedicated networking events. These included the Welcome Reception on June 16, the Women in Data + AI meetup, a Data + AI Summit Happy Hour sponsored by WinWire and Microsoft on June 16, a Founders Happy Hour co-sponsored by Microsoft and Databricks on June 17 and Data After Hours on June 17 at Oracle Park, home of the San Francisco Giants, featuring a performance by the Chainsmokers.
Hallway and booth conversations repeatedly surfaced three concerns: rising compute costs from agentic workloads, agents still sitting in pilots rather than production and the growing operational complexity of the Databricks platform itself.
Apps and agents Hackathon
The Databricks Data + AI Summit 2026 also included a multi-day Apps & Agents Hackathon, organized in partnership with OpenAI. Teams worked across several days to build proof-of-concept agentic data applications addressing social-impact use cases, then presented their projects. Unlike a sprint-format hackathon, the multi-day structure gave participants time to design, build, iterate and present working applications on the Databricks platform.
Days 3 and 4 completed the story that Databricks started in the keynote.
The first two days answered what the company built.
The final two days focused on how organizations can deploy it.
Conclusion
And that’s a wrap! Databricks Data + AI Summit 2026 just dropped one of the company’s most ambitious product plans yet. Genie One, Lakehouse//RT, LTAP, Lakebase, and Unity AI Gateway were definitely the stars of the show, but the bigger picture is Databricks’ effort to bring data, AI, analytics, and governance together on one open platform. The real challenge begins now. As these new features move from demos to real-world use, companies will see how well they can break down data barriers, streamline operations, and give AI systems the context they need to drive real business results on a large scale.
Additional resources
- Databricks Data + AI Summit 2026 on-demand keynotes
- Genie One press release, Databricks newsroom
- LTAP press release, Databricks newsroom
- Panther acquisition announcement
- Lakewatch announcement press release, Databricks newsroom
- LakeFlow blog: a new era of agentic data engineering
- ZeroBus Ingest GA blog
- Lakehouse//RT blog: real-time performance on a unified lakehouse
- Agent Bricks Data + AI Summit 2026 blog
- Omnigent introduction blog, Databricks
- Azure Databricks Data + AI Summit 2026 announcements
- LakeBridge data warehouse migration tool
- Omnigent on GitHub
- Linux Foundation announces OpenSharing project
- Genie Ontology and Genie Agents blog, Databricks
- Apache Iceberg v3 and format unification blog




